Genomics Reporting Implementation Guide
4.0.0-cibuild - CI Build
![]()
Genomics Reporting Implementation Guide
4.0.0-cibuild - CI Build
![]()
Genomics Reporting Implementation Guide, published by HL7 International / Clinical Genomics. This guide is not an authorized publication; it is the continuous build for version 4.0.0-cibuild built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/genomics-reporting/ and changes regularly. See the Directory of published versions
| Page standards status: Informative |
This page defines the core profiles and concepts that would be expected to be present in most genomic reports, regardless of type, and how those profiles relate to each other. Concepts covered include the genomic report itself and the high-level categories of observations and other elements that make up the report, such as patient, specimen, variants, haplotypes, genotypes, etc. See the profile pages for more detailed information and guidance.
This table describes the categories of data contained in this implementation guide.
| Category | Description |
|---|---|
| Genomic Report | Groups together all the structured data being reported for a genomic testing. |
| Genomic Study | Delineates relevant information of a performed genomic study. A genomic study might comprise one or more analyses, each serving a specific purpose. |
| Genomic Findings | These are observations about the specimen's genomic characteristics. For example, a chromosomal abnormality, genotype, haplotype, or variant that was detected. |
| Genomic Implications | These represent observations where the Observation.subject is typically the Patient and the Observation.derivedFrom should refer to Genomic Findings or Molecular Biomarkers. For example, "Patient may have increased susceptibility to heart attacks" |
| Molecular Biomarkers | These are observations describing Molecular Biomarkers, which encompasses laboratory measurements of human inherent substances such as gene products, antigens and antibodies, or complex chemicals that result from post-translational processing of multi-gene products. |
| Recommended Actions | Specific actions be taken, such as genomic counseling, re-testing, adjusting drug dosages, etc. - driven by the results found. |
| Contextual Resources | Other resources that provide contextual details. |
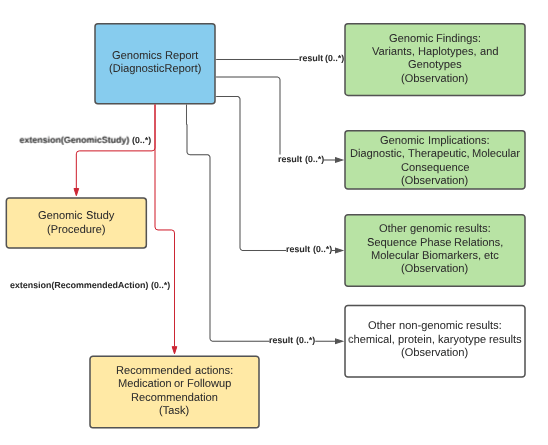
The genomic report is the focus of all genomic reporting. It conveys metadata about the overall report (what kind of report it was, when it was written, who wrote it, final vs. draft, etc.). It also typically includes a rendered version for review by a clinician. It also groups together all relevant information found as part of the genomic analysis (Rules for relevancy will depend on the type of testing ordered, the reason for testing and the policies of the lab). Most of the structured genomic information is expressed as FHIR Observations. Any recommendations that come with the report are expressed as FHIR Tasks.
Genomic Report Overview
Genomic Report, Genomic Findings, Genomic Implications, Genomic Study, Recommended Actions
In the R5 release, the GenomicStudy resource was introduced. This resource is intended at capturing relevant information about the reasons, purpose, and performers of the study. It also provides technical endpoints to access the data. It could be a logical aggregator for complex analyses.
These features are important to appropriately manage and structure the metadata about a genomic study. As such, this guide has introduced new profiles to 'backport' these features for this R4 based implementation guide. Refer to these profiles for additional details:
GenomicStudy profile to represent the study level metadata.
GenomicStudyAnalysis profile to represent the analysis level metadata.
The GenomicStudy instance SHOULD be referenced from a report and CAN be referenced by various observations.
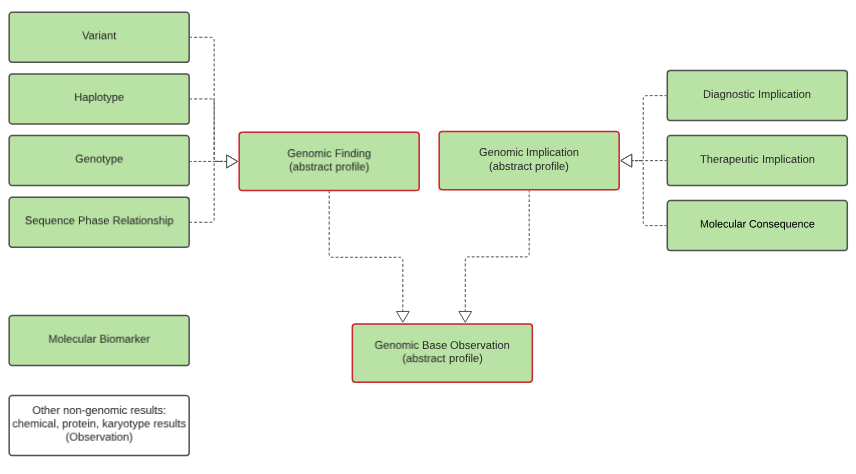
Observations are the core representation of structured genomic information. This guide defines a number of Observation profiles, with common underlying components and constraints being inherited from abstract profiles as shown in the following diagram. The profiles and their specific usage will be defined in more detail below and on the other pages of this guide.
All genomic observations are derived from a common abstract profile that asserts they should have a category, effective date, issued date and status.
Genomic Observations
Genomic Base, Genomic Finding (abstract), Variant, Haplotype, Genotype, Sequence Phase Relationship, Genomic Implication (abstract), Therapeutic Implication, Diagnostic Implication, Molecular Consequence, Genomic Annotation
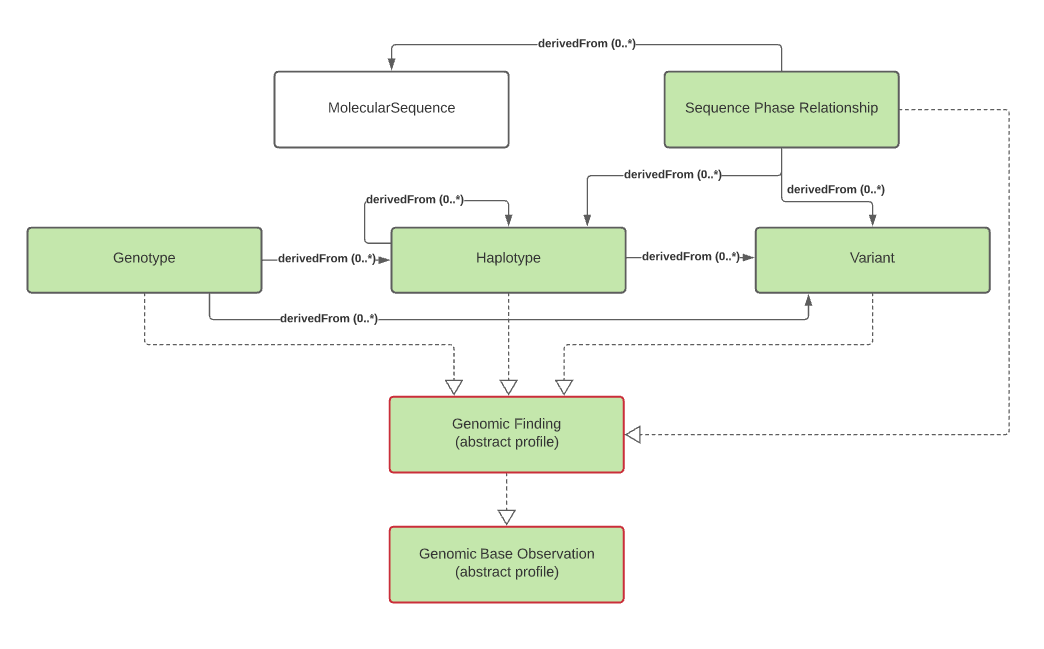
The primary focus of genomic testing is making Genomic Findings. These are the fine and/or coarse-grained descriptions of a specimen's genomic characteristics. It is this information that leads to the GenomicReport.conclusion and GenomicReport.conclusionCode for the report, as well as Genomic Implications that are used to convey the potential impact of the genomic findings for the subject of the test.
Genomic Findings
Genomic Finding, Genotype, Haplotype, Variant (or see Variant Reporting), Sequence Phase Relationship
STU Note: At present, implications are noted as explicit observations about the patient/subject. However, it's not clear this is the correct approach. The work group is evaluating introducing a new resource that allows conveying "knowledge" about a variant in a patient-independent way. This would allow saying "this variant is associated with an increased risk of cardiovascular disease" rather than "based on this variant, the patient is at an increased risk of cardiovascular disease", which isn't necessarily a determination the reporting organization may wish to assert. Feedback is welcome.
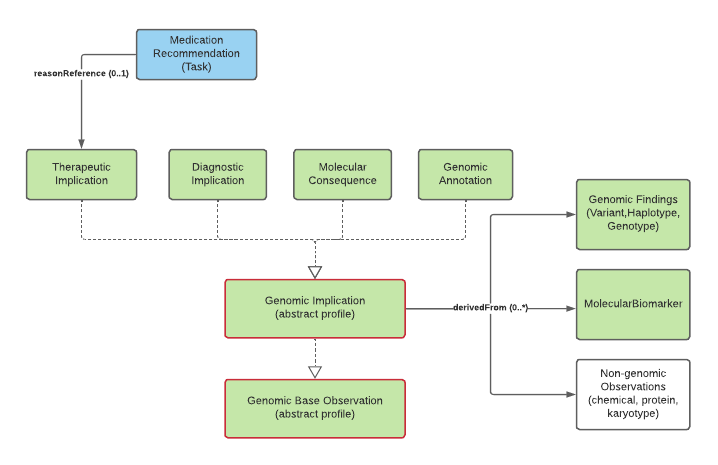
Genomic Implications
Genomic Implication, Therapeutic Implication, Diagnostic Implication, Molecular Consequence, Genomic Annotation
Genomic Implications are assertions of likely effects of genomic results on the patient, tumor, or other subject. Implications are relevant for areas of genomic testing including inherited disease, pharmacogenomics and somatic. For inherited diseases, a diagnostic implication indicates the likelihood of inheritance of a particular disease (the associated-phenotype) as well as how inheritance is likely to occur (mode-of-inheritance). For other more specific guidance, see the pharmacogenomics and somatics pages.
The term 'biomarker' is broad, encompassing observable characteristics that indicate normal or abnormal biological processes and that are often used to assess prognosis or guide therapy. In the broad sense, many clinical and laboratory observations might be considered a 'biomarker'. 'Molecular biomarker' is likewise broad, primarily encompassing laboratory measurements of human inherent substances such as gene products, antigens and antibodies, complex chemicals that result from post-translational processing of multi-gene products, etc. Molecular biomarkers include many different types of measurements, such as presence or absence of a chemical, or the level of a chemical. Here, we are primarily interested in those molecular biomarkers that have associated therapeutic implications, particularly in precision cancer care, including but not limited to: cell receptor levels (e.g. ER, PR, HER2); molecular sequence adjacent observations (e.g. microsatellite instability, tumor mutation burden, gene promoter methylation); cell receptor ligands (e.g. PD-L1); proteins, antigens, and antibodies (e.g. HLA type). These sorts of observations may be represented by the Molecular Biomarker profile.
These actions can be specific recommendations be taken and are driven by the results found. These can be a Follow-up Recommendation which can be used to indicate when some sort of follow-up (additional testing, genetic counseling) is required, or a Medication Recommendation which can be used to propose medication recommendations based on the results of the test.
There are a number of resources that are used within this guide to provide additional data as both input and output of the test.
The ServiceRequest resource typically represents a clinician order. It can also represent a lab-side filler order, a reflex order or even a plan or recommendation. These uses are distinguished via the intent element. The primary test to perform is captured in ServiceRequest.code. However, qualifications on what variants, medications, diseases, and other aspects to search on can be conveyed using the orderDetail element. The service requests and the reports resulting from them can be associated to patients, to specimens or both.
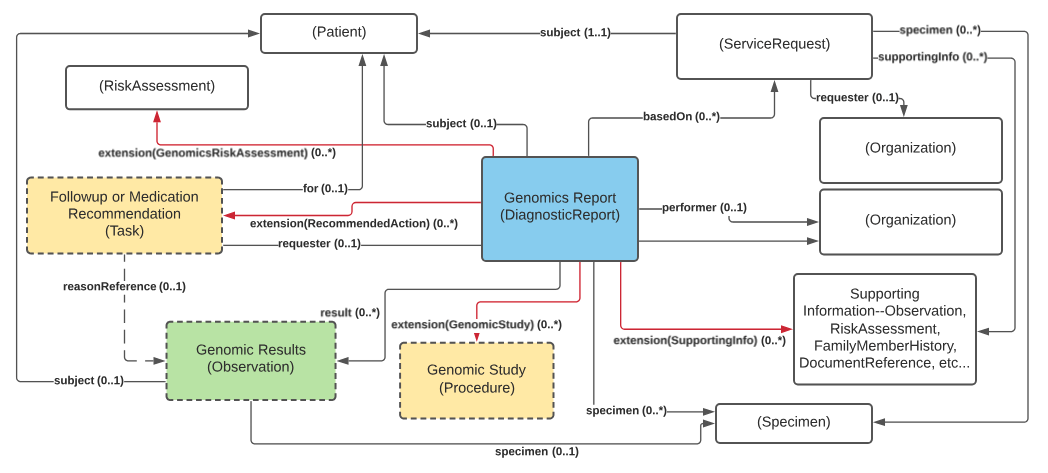
Orders can point to other sources of information used to support the analysis performed as part of genomic testing. Genomic reports can refer to information that was considered as part of the report - whether provided as part of the order or made available subsequently by the patient or clinicians or otherwise retrieved. The figure above shows these relationships through the extension SupportingInformation, which can be to any resource but would typically reference Observations, FamilyMemberHistory records (including records that comply with Family member history for genomics analysis and RiskAssessments.
To allow searching and appropriate navigation, the diagnostic report, observations, and tasks must be able to stand on their own. They need to be related to the associated patient and/or specimen, the order that initiated the testing, the lab that performed the testing, etc. FHIR design principles dictate that these associations be present on every resource instance. That's because each resource could be accessed on its own as part of a query response, embedded in a document or message, passed to a decision support engine, etc. However, this is still relatively lightweight because the information is included by reference only.
The following diagram shows the relationships between the diagnostic report, observations, and other elements used in the profile. Note that there is no expectation that all relationships will point to the same instances. In special cases, a genomic report may involve multiple patients or multiple specimens. As mentioned, the extends, summaryOf can be used well to provide additional organization.
Key points to take from this diagram:
requisition identifier.GenomicReport and CAN be linked from Observations. Genomic Study can reference multiple Genomic Study Analysis instances, which can reference input and output files.Observation.derivedFrom attribute. For example, in a genomic report, it's not acceptable to imply "patient is an increased metabolizer of drug X" without also indicating the variant, haplotype or genotype found that supports that implication.The following is derived from the CORE FHIR guidance on Diagnostic Report Resource and Observation Resource.
For receivers of genetic reports, to ensure all clinically relevant information is processed, consumers of Genomic Diagnostic reports MUST navigate through all hasMember relations, and navigate through derivedFrom when processing Genomic Diagnostic reports.
For senders of Genomic Diagnostic reports, it is up to receiving systems to arrange/use the genomic observations appropriately. However, some systems may only process just the first layer of a DiagnosticReport.results. Thus, when sending the report and results, we recommend including result links to all the genomic observation results being returned. For more complex reporting use cases, consider using the summaryOf extension on DiagnosticReport for creating meaningful subsets of observations.
As a note on querying, the relationships indicated by hasMember, derivedFrom and the computable meaning conveyed by observation.code and component.code are critical for specificity in querying and getting comprehensive search results. Additionally, values found in elements like component.value and observation.value are useful as well. However, the meanings of the values are predicated on by the component.code or observation.code to which they associate. There is a page in this IG with query guidance that shows how to use components, relationships (references) and the iterative hasMember to find results. The use of a grouping observation does not influence the ability to query. For example, the profile of a variant contains a value for the gene name component. Querying for all variants for the patient in a given gene can be done through the gene name component.
This implementation guide utilizes FHIR profiling to define constraints on base resources, thereby offering an interoperable framework for reporting structured genomic data. While this guide seeks to describe concepts necessary for a complete genomics report, it's important to acknowledge potential areas where flexibility is required. Here are instances and examples illustrating where such flexibility might be necessary:
Prior to incorporating new data, implementers should carefully review the implementation guide to determine if the concept exists within its structure but is represented differently. Only upon confirming the absence of a matching concept should they proceed with introducing a new data element. This precaution is crucial, as any deviation from the guide reduces implementation consistency and consequently undermines interoperability.
Considering this, we acknowledge that some implementers may need to utilize this flexibility. Therefore, here is further guidance on suitable options.
This guide introduces several extensions where specific attributes for reporting genomic data are identified. However, additional extensions can be introduced for specific implementations as needed. Implementers may use the extensibility features built into FHIR.
When constraining attributes that can contain multiple values, the FHIR concept of slicing is used. All defined slices are 'open,' signifying that while specific rules should be adhered to when feasible, implementers have the freedom to include additional data as needed.
The guide mandates specific codes in certain cases, while permitting the use of other codes (such as lab-specific ones). For instance, in Observation.code, profiles require a specific code, yet alternative codes are permissible within Observation.code.coding. Implementations must adhere to the guidance outlined for "Additional Codes" available here.
In Observation.component, supporting results can be described within Observation.component.code, with corresponding values provided in Observation.component.value[x]. For further guidance on grouping components, please refer to the guidance available here.
When establishing references between resources, the guide employs slices to specify the type of resources we recommend referencing. However, references to other resources remain valid if permitted in the base specification. For instance, in the Genomic Report, the result element is sliced according to the various Observation profiles defined in this guide. When incorporating additional Observations, they should still be referenced using result to ensure discoverability of all instances.
Specifically for references between Observations, there are two attributes used to define relationships between instances: hasMember and derivedFrom. For further guidance on their appropriate usage, please refer to the information available here.
When the guide references a ValueSet, a binding strength signifies the degree of flexibility afforded to implementers in selecting codes. With few exceptions, the guide specifies bindings that permit implementers to choose alternative codes when the designated ValueSet lacks suitable options. Implementers are encouraged to align their codes with those suggested by the guide whenever feasible.
STU Note: The Clinical Genomics Work Group actively seeks feedback from the community regarding additional structured data necessary for a comprehensive report. We want to hear about profiles, codes, values, and extensions that stakeholders have found beneficial while implementing the structures and use cases outlined in this guide. For ways to contact the work group, please refer to here.
IG © 2025+ HL7 International / Clinical Genomics. Package hl7.fhir.uv.genomics-reporting#4.0.0-cibuild based on FHIR 4.0.1. Generated 2026-01-30
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change