ACT-NOW Implementation Guide
0.5.0 - ci-build
![]()
ACT-NOW Implementation Guide
0.5.0 - ci-build
![]()
ACT-NOW Implementation Guide, published by Te aho o te kahu - Cancer Control Agency. This guide is not an authorized publication; it is the continuous build for version 0.5.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/davidhay25/actnow/ and changes regularly. See the Directory of published versions
There are at least a couple of options for the input API using the RESTful API.
The direct REST API involves the the client making individual API calls for each interaction. For example, to record that a medication was given, then client retrieves the appropriate patient Id and cycle CarePlan id, creates the MedicationAdministratoion resource with the appropriate references, and POSTs the MedicationAdministration to the server. This results in an extremely 'chatty' API interaction, with a increased risk of client errors leading to data corruption if the wrong resource is created or updated or incorrect reference resources are chosen.
This can be mitigated to some degree if each client had its own server and/or has control over the resource ids (updating using the PUT interaction), at the expense of increased system complexity.
In this scenario, all interactions are by using Transaction bundles, where updates and references to other resources can be determined by their identifier using conditional creates or
conditional updates. This has the advantage of off loading much of the work to the server and allows multiple resources to be created / updated in a single interaction.
While it does require the client to maintain the unique identifiers (the resource element identifier - not the resource id), this is much simpler and safer to manage than having to use the resource id especially when different clients are updating the server. The supplier still needs to maintain unique identifier values, but this is made easier by using unique 'system' values for each supplier.
This is the approach taken in this guide, as seen in the following diagram
There is a further requirement in this guide that the resource id's are UUID's, even if the physical id of the resource on the CanShare server is known.
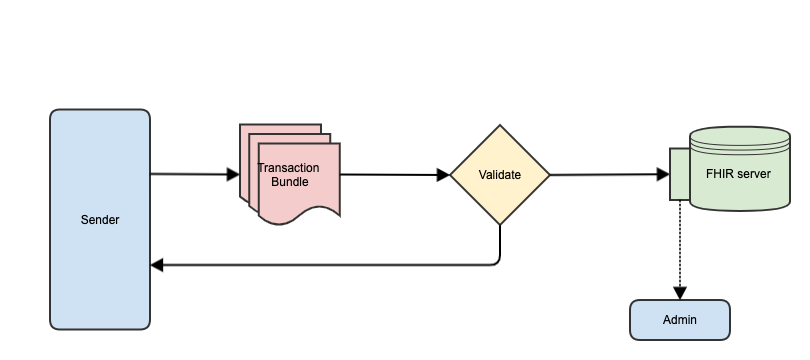
This section describes how data is sent from client applications to the system, assuming that conditional updates can be used.
The current API uses conditional updates (sometimes known as an upsert) in a FHIR transaction to receive data from suppliers. The resource identifier is the element used to discriminate during the update or create operation. The bundle contains all resources referenced by any other resource within the bundle, and uses UUID's as resource ids.
In some cases, conditional create may also used where the resource must be present in the bundle to allow the server to resolve the resource ids for referencing, but the resource is not intended to be updated if already present. The Patient resource is an example where this might be appropriate.
Conditional delete operations are not used, as errors can be managed with appropriate resource status updates and a Conditional update.
add note that the NHI mst be used in the conditional operation
An identifier is an alternate way of identifying a resource. Unlike the resource id, the value of the identifier does not change if the resource is moved between servers (it is considered a business identifier rather than a structural/logical one which is the id).
Note that the identifier element has a datatype of identifier as well the name.
The identifier datatype is a complex datatype and has number of child elements, of which 2 are the most useful - system and value.
The identifier.system element describes the domain within which the identifier.value is unique. Existing examples are medical record numbers, passport numbers and driving license.
Each potential supplier of information will be assigned a system value (which is a url). Alternatively, if the supplier has one which is not being used by any other supplier then that could be used.
The same system could be used for any resource type, providing that the value remains unique within that system. Alternatively a separate system per resource type could be used.
The identifier.value element contains the actual value of the identifier - eg the NHI number.
The Bundle is a FHIR resource that contains resources within Entry elements. Each entry has the resource to be updated, and other metadata as required for the particular operation.
To support the need to update based on the resource identifier, conditional updates are required for all resources in the bundle.
In a conditional update (sometimes called an 'upsert'), the entry contains a number of specific elements:
Here's an example of a CarePlan with an identifier with a system value of http://example.org and a value of abc1234 being created or updated.
"entry": [
{
"fullUrl": "urn:uuid:ad9ae703-e6a3-41f7-90e8-b6f6ff9e3742",
"resource" : {....},
"request" : {
"method":"PUT",
"url": "CarePlan?identifier=http://example.org|abc1234"
}
}
]
need to think further about 'planned' resources coming through and what to do when that changes.
notes on which med resource to use (mad admin vs med request). Issue is that 'planned' resources are being sent through
deleting data - eg if regimen changes.
A bundle containing resources to be saved in the server can have any number of resources. The following constraints apply.
The uuid(Universally Unique ID) is used as a unique id within the bundle, including references between resource (ie to reference another resource you use the uuid)
The server will locate an existing resource based on the identifier or create a new one if none exist as described above. The server will then update the references between resources to use that id internally,
Here's an example of resources and resource references in a sample bundle. Note the presence of the 'fullUrl' element in the bundle which must be present (it matches the id).
{
"resourceType": "Bundle",
"type": "transaction",
"entry": [
{
"fullUrl": "urn:uuid:c0f81fc6-a8cd-437d-af98-3c1b8e65a264",
"resource": {
"resourceType": "Patient",
"id": "c0f81fc6-a8cd-437d-af98-3c1b8e65a264"
"identifier": [
{
"system": "http://clinfhir.com",
"value": "patient5"
}
],
... snip ...
},
"request": {
"method": "PUT",
"url": "Patient?identifier=http://clinfhir.com|patient5"
}
},
{
"fullUrl": "urn:uuid:ad9ae703-e6a3-41f7-90e8-b6f6ff9e3742",
"resource": {
"resourceType": "CarePlan",
"id": "ad9ae703-e6a3-41f7-90e8-b6f6ff9e3742",
"identifier": [
{
"system": "http://clinfhir.com",
"value": "cp5"
}
],
... snip ...
"subject": {
"reference": "urn:uuid:c0f81fc6-a8cd-437d-af98-3c1b8e65a264"
}
},
"request": {
"method": "PUT",
"url": "CarePlan?identifier=http://clinfhir.com|cp5"
}
},
... snip ...
}
As described earlier, the identifier is the mechanism used to locate resources for update if needed.
This is needed to support validation on the received data, as the data is being used for analytics and data quality is paramount.
Even if the resource already exists in the server, it should still be present in the bundle. eg the Patient resource will always be present. This approach makes the overall design much simpler - especially for references as otherwise the client would need to first query the server to locate the target reference id (eg the patient id), then create the source resource.
There are a number of strategies for the client to create the bundle, depending on their internal capabilities. At the least, it must maintain unique identifiers for each resource within its database. These may or may not be in the FHIR format as long as they are unique within the clients system, at least within the resource type (so the combination of identifier.system & identifier.value is unique).
Data can be sent either as new/updates only (incremental) or all data for a patient. The approach taken will depend on whether the client can track internally resources that have been submitted (incremental update) or whether it must send a complete dump of all the data for a patient if there are any changes to that patients data.
The incremental approach will result in smaller bundles (as only changed resources and resources they reference need to be sent) and will allow allow the server to track changes to resources over time (eg a changing CarePlan status). However, this does add to the complexity of the solution.
If the sender cannot track which resources have been sent to the system, then when any patient data changes, all data needs to be sent (or re-sent) to the server. It is suggested that there should be a single bundle per patient as this will keep the bundle size as small as possible. It also means that if there is a validation error, then only that patient will need to be re-sent.
Here's an example high level flow.
For each patient that has had an update (new or changed data) since the last time a bundle was sent:
In this scenario, the client is able to track which resources have (successfully) been sent to the system and can create bundles that only contain updated or new resources.
The flow is pretty much the same as for the complete patient refresh except that only new or updated resources are included in the bundle. (plus any other resources which they reference - like Patient)
If a CarePlan was created incorrectly, then it should be re-submitted (with the same identifier) setting that status to 'entered-in-error'.