FHIR CI-Build

 Clinical Reasoning
Clinical ReasoningThis is the Continuous Integration Build of FHIR (will be incorrect/inconsistent at times).
See the Directory of published versions 
| Responsible Owner: Work Group Clinical Quality Information | Standards Status: Normative |
Note to Balloters: Key changes made since FHIR 6.0.0-ballot4:
- Non-compatible Changes
- None
- Compatible, Substantive Changes
- None
- Non-substantive Changes
- FHIR-55079
- FHIR-53433
All Changes (including Technical Corrections not listed above):
- None
Note that throughout this section, the following terms are used:
Quality measures help improve the quality of health care through a consistent and accountable approach to evaluating care delivery. The Measure resource represents a structured, potentially computable definition of a health-related measure such as a clinical quality measure, public health indicator, or population analytics measure. The resource builds on the general approach to representing knowledge artifacts and adds the metadata and structure information that is specific to measures:

Quality measures follow a general structure that defines:
Metadata: Information about the measure such as identity, purpose, and usage.
Population Groups: Groups of population criteria that define a specific measurement or rate. A given Measure may include any number of population groups, each defining a separate calculation including scoring method and population criteria.
Measures have metadata just like any other conformance or knowledge artifact in FHIR. This includes metadata elements that are specific to measures and not needed for other knowledge artifacts. For example metadata elements that are common across many knowledge artifacts including measures, are identifier, version and date. Metadata elements that are specific to measures include measure scoring, rate aggregation, clinical recommendation statement and improvement notation. For more information about each metadata element see the Measure Resource.
Mappings from the V3 to the FHIR terminologies can be found in the Quality Measure IG .
Each population group in a measure specifies how to calculate the measure using the following main elements:
These calculation elements provide a flexible mechanism for describing measure specifications, along with a complete set of scoring methods that align with industry standard approaches for representing quality measure specifications. In addition, the Measure and MeasureReport resources are built to be extended, so that implementation guides can be introduced to provide additional guidance and extend the scoring methods that can be used.
At their most basic, Measures evaluate items within a defined perspective and assign those items to populations. The perspective from which those items are counted is the Measure's subject such as Patient or Location. The type of the evaluated items that make up the populations is called the Measure's basis, and one can say that a Measure is based on a FHIR resource type, such as Encounter or Procedure.
The subject element of the population group indicates the intended subjects of a measure, or who the measure is about. Measures are often about Patients, so the population group subject is typically Patient, but Practitioners, Organizations, Locations, or even Devices can also be the subject of a measure. The subject determines the perspective from which the various criteria expressions in a measure are evaluated. For example, in a Patient-subject measure, the expression [Observation] refers only to the observations for a particular patient. If no subject is specified for the population group, the context is unfiltered, i.e. population criteria are evaluated from the perspective of the entire system, rather than from the perspective of a particular subject.
The group.basis and group.basisRequirement elements specify the types of elements in the population(s). Population Quality Measures generally fall into two categories: subject-based, and non-subject-based. In general, subject-based measures count the number of subjects in each population, while non-subject-based measures count the number of items (such as encounters) in each population. Although the calculation formulas are conceptually the same for both categories, for ease of expression, population criteria for subject-based measures indicates whether a subject matches the population criteria (true) or not (false). Non-subject-based measures return the items to be counted such as encounters or procedures. For example:
When the intended population basis matches the subject type, the measure is referred to as "subject-based." For a subject-based measure, the basis is boolean because the subject and the population basis are the same, and the population criteria define yes/no values for each element in the population. For measures that have a population basis that is different than the subject, the basis element specifies the type of elements in the population.
In addition to the basis element, the basisRequirement element may be used to allow for measures that are counting multiple types of items. For example, a measure counting the number of eligible CT scans performed in a hospital outpatient setting may characterize an eligible CT scan using either a DiagnosticReport, or an Observation, depending on how the information is modeled in the available clinical systems. To allow for this, the measure would specify two different basisRequirements:
<basisRequirement>
<type value="DiagnosticReport"/>
<codeFilter>
<path value="code"/>
<valueSet value="http://example.org/ValueSet/ctscan-diagnostic-report-codes"/>
</codeFilter>
</basisRequirement>
<basisRequirement>
<type value="Observation"/>
<codeFilter>
<path value="code"/>
<valueSet value="http://example.org/ValueSet/ctscan-observation-codes"/>
</codeFilter>
</basisRequirement>
If multiple basisRequirements are specified, criteria expressions may return data that satisfies ANY basisRequirement. A data element satisfies a basisRequirement if the instance `is` of the type, conforms to ALL the specified profiles, and matches ALL the codeFilters. basisRequirements SHALL specify type, MAY specify profile and codeFilter, and SHALL NOT specify dateFilter, valueFilter, limit, or sort. If basis is specified, any basisRequirement SHALL be consistent with the specified basis (i.e. the type of each basisRequirement SHALL be the same type as, or a subtype of the basis type).
To summarize, the context of a measure is indicated using the subject element of the FHIR resource, and it indicates what types of resources the measure is about. The basis indicates what is being included in the measure populations during measure calculation. If the subject's type is the same as the intended population type, then the basis is boolean and expression criteria indicate whether a subject is included in a population or not.
As with other knowledge artifacts, logic is included by referencing a Library resource.The Library resource is a general purpose container for clinical knowledge artifacts. It can be used to describe and expose existing knowledge such as logic and information model descriptions, as well as to describe a collection of knowledge artifacts. Measures should reference only one Library, the primary measure library, and that library should contain all the named expressions required to define the measure structure. For more information on using libraries with CQL and FHIR, refer to the Libraries topic in the Using CQL with FHIR Implementation Guide.
Note that this approach does not preclude sharing of logic between measures, it only requires that that sharing be explicitly done as dependencies within the referenced libraries, rather than allowing a measure to reference multiple libraries directly.
A measure can include various population criteria, depending on the measure scoring being used. The following table shows which population criteria types are required (R), optional (O), or not permitted (NP) for proportion, ratio, continuous variable, cohort, and attestation measures. Note that these are the relationships for these scoring types. Additional population criteria types and scoring methods can be defined in implementation guides.
| Measure Scoring | Initial Population | Denominator | Denominator Exclusion | Denominator Exception | Numerator | Numerator Exclusion | Measure Population | Measure Population Exclusion |
|---|---|---|---|---|---|---|---|---|
| Proportion | R | R | O | O | R | O | NP | NP |
| Ratio | R | R | O | NP | R | O | NP | NP |
| Continuous Variable | R | NP | NP | NP | NP | NP | R | O |
| Cohort | R | NP | NP | NP | NP | NP | NP | NP |
| Attestation | O | O | O | O | O | O | O | O |
The Measure resource identifies specific named expressions within the referenced primary measure library that define the criteria for each population. For example, the following fragment illustrates the population criteria definitions for the CMS146 measure example:
<group>
<linkId value="CMS146-group-1"/>
<population>
<linkId value="CMS146-group-1-ip"/>
<code>
<coding>
<system value="http://terminology.hl7.org/CodeSystem/measure-population-type"/>
<code value="initial-population"/>
</coding>
</code>
<criteria value="CMS146.InInitialPopulation"/>
</population>
<population>
<linkId value="CMS146-group-1-num"/>
<code>
<coding>
<system value="http://terminology.hl7.org/CodeSystem/measure-population-type"/>
<code value="numerator"/>
</coding>
</code>
<criteria value="CMS146.InNumerator"/>
</population>
<population>
<linkId value="CMS146-group-1-den"/>
<code>
<coding>
<system value="http://terminology.hl7.org/CodeSystem/measure-population-type"/>
<code value="denominator"/>
</coding>
</code>
<criteria value="CMS146.InDenominator"/>
</population>
<population>
<linkId value="CMS146-group-1-denex"/>
<code>
<coding>
<system value="http://terminology.hl7.org/CodeSystem/measure-population-type"/>
<code value="denominator-exclusion"/>
</coding>
</code>
<criteria value="CMS146.InDenominatorExclusions"/>
</population>
</group>
The following sections describe the base scoring methods defined in this specification. For a more formal treatment of these scoring methods, as well as detailed examples and ongoing guidance, refer to the Quality Measure implementation guide.
A proportion scoring measure is defined as the result of a fraction (number of events in the numerator divided by the number of events in the denominator). Proportion measures typically define an initial population, then denominator and numerator inclusion and exclusion criteria.
Take the following steps to add labels to each case to determine population membership:
Initial Population criteria, add the label initial-population.Denominator criteria, add the label denominator.Denominator Exclusion criteria, add the label denominator-exclusion.Numerator criteria, add the label numerator.Numerator criteria, if the case meets Denominator Exception criteria, add the label denominator-exceptionNumerator Exclusion criteria, add the label numerator-exclusion.Population counts are then determined by simply counting the number of cases that are labeled with each population type code.
The performance rate is then the number of patients in the Numerator (accounting for exclusions), divided by the number of patients in the Denominator (accounting for exclusions and exceptions). Performance rate can be calculated using this formula:
Performance rate = (Numerator - Numerator Exclusion) / (Denominator - Denominator Exclusion - Denominator Exception)A ratio scoring measure is defined as the result of a ratio calculation. This is similar to a proportion scoring, with the exception that the numerator and denominator may be drawn from different initial populations, and are reported as a ratio (i.e. N/D), rather than a decimal. Ratio measures typically define initial population(s) and then numerator and denominator inclusion and exclusion criteria.
Take the following steps to add labels to each case to determine population membership:
Initial Population criteria, add the label initial-population. Note that if the ratio measure uses multiple initial populations, one for the numerator, and one for the denominator, different labels must be used to distinguish the populations.Denominator criteria, add the label denominator.Denominator Exclusion criteria, add the label denominator-exclusion.Numerator criteria, add the label numerator.Numerator Exclusion criteria, add the label numerator-exclusion.Population counts are then determined by simply counting the number of cases that are labeled with each population type code.
The performance ratio is then the number of patients in the Numerator (accounting for exclusions), over the number of patients in the Denominator (accounting for exclusions and exceptions). Performance rate can be calculated using this formula:
Performance ratio = (Numerator - Numerator Exclusion) / (Denominator - Denominator Exclusion)Note that ratio measures may also specify numerator and denominator measure observations, as an alternative to simply counting the members of the population (i.e. a ratio of continuous variable measures). This is useful for modeling measures such as a Standardized Infection Ratio, where the denominator is estimated based on population estimates, or predicted based on a statistical model. For an illustration of this approach using a Catheter Associated Urinary Tract Infection measure, refer to [Cooking With CQL - Session 93 - CAUTI Example](https://github.com/cqframework/CQL-Formatting-and-Usage-Wiki/blob/master/Source/Cooking%20With%20CQL/93/CAUTI.md).
A continuous variable scoring measure is defined by a measure observation calculation performed for each member of the population. Continuous variable measures typically define an initial population, then measure population inclusion and exclusion criteria, as well as a measure observation.
For example, a continuous-variable measure may define time from check-in to time of antibiotic administration. Note that measure observations are actually a function in terms of the members of the population, not a filtering population criteria. Rather, measure observations are data elements, to be collected from each subject that satisfies the measure population inclusion and exclusion criteria, which are used to calculate the results for each member of the population.
Take the following steps to add labels to each case to determine population membership:
Initial Population criteria, add the label initial-population.Measure Population criteria, add the label measure-population.Measure Population Exclusion criteria, add the label measure-population-exclusion.Population counts are then determined by simply counting the number of cases that are labeled with each population type code.
The measure score is then determined by calculating the Measure Observation for each case that is labeled measure-population and not measure-population-exclusion, and aggregating the resulting measure observations using the aggregateMethod.
A cohort scoring measure is simply the definition of a population, and the score is a count of the members of that population. Cohort measures typically define only an initial population to determine membership. Cohort measures are often used to determine baseline populations for a collection of measures. With supplemental data, cohort measures are often used as data collection tools to define a set of patients of interest, and a set of data elements to be collected for each member of that population.
An attestation scoring measure indicates that the reporter of the measure is attesting the measure score. This is typically used for true/false attestations, but can be used for other types of measure scores as well. The key distinction is that the measure is not computably represented (i.e. as a calculation or aggregation performed on some data in the reporting system), but rather is a simple attestation made by the measure reporter.
Quality measures often specify multiple rates, with different population crtiteria for each rate. This is different than stratifying the scores for the same population. For quality measures that contain multiple rates, the Measure will contain multiple group elements, where the criteria are specified once for each group. The linkId attribute of the group element is used to uniquely identify the group within the measure, as well as within the quality reporting results.
Supplemental data are descriptive in nature and do not represent an evidence-based quality opportunity, rather they may provide useful additional contextual information about a measure population, or support quality program requirements such as Helth IT certifiaction. Strata are an integral component of the core measure specification. Each evidence-based stratum represents significant clinical or policy rationale for subdividing the measure population.
).Measure stratification is specified using the stratifier element of the Measure resource. Stratification criteria are specified either as a reference to a CQL named expression within a Library (e.g. CMS146.AgesUpToNine), or as FHIR resource paths (e.g. Patient.deceased). When the stratification criteria is an expression, the stratification will yield as many result strata as the expression returns. For example, if the expression returns a boolean, then there would be two stratification groups: true and false. When the stratification criteria is a FHIR resource path, there will be as many stratification groups as discovered values for the resource path.
Criteria-based Stratifiers
Using criteria-based stratifiers is the most straightforward stratification approach as it is simply another set of population criteria for the measure. The expressions used to define criteria-based stratifiers must be consistent with the basis of the measure (i.e. they must return the same type as all the other population criteria expressions in the measure. For example, consider stratification into three age ranges: 0-20, 21-40, 41+.
NOTE: These examples are deliberately ignoring the measurement period, as well as the fact that age is a moving point now. Real measures will of course need to take these factors into account, but these examples are focusing solely on the structural representation of the various approaches to stratification.
Subject-based
Percentage of patients with a well-visit
define "Denominator":
Patient.active is true
define "Numerator":
exists ([Encounter: "Well-Visit Encounter Codes"])
Criteria-based stratification by age range
define "Stratifier P0Y--P21Y":
Patient.ageInYears() between 0 and 20
define "Stratifier P21Y--P41Y":
Patient.ageInYears() between 21 and 40
define "Stratifier P41Y--P9999Y":
Patient.ageInYears() > 41
Non-subject-based
Percentage of well-visits with a blood pressure observation
define "Denominator":
[Encounter: "Well-Visit Encounter Codes"]
define "Numerator":
[Encounter: "Well-Visit Encounter Codes"] E
with [Observation: "Blood Pressure Observation Codes"] O such that O.issued during E.period
Criteria-based stratification by age range
define "Stratifier P0Y--P21Y":
[Encounter: "Well-Visit Encounter Codes"] E
where Patient.ageInYears() between 0 and 20
define "Stratifier P21Y--P41Y":
[Encounter: "Well-Visit Encounter Codes"] E
where Patient.ageInYears() between 21 and 40
define "Stratifier P41Y--P9999Y":
[Encounter: "Well-Visit Encounter Codes"] E
where Patient.ageInYears() > 41
Value-based Stratifiers
Value-based stratifiers are expressed as a set of stratifier components, each one identifying a path or an expression that returns a value of a type other than the basis. Using the same simple example measures as above:
Subject-based, valued-based, as a path, stratification by gender:
<stratifier>
<component>
<criteria>
<expression value="gender"/>
</criteria>
>/component>
</stratifier>
Note that with value-based stratifiers represented as a path, the value is an expression written from the perspective of the measure subject (Patient in this case) for subject-based measures, but the measure basis for non-subject-based measures.
Subject-based, value-based, as an expression
define "Age Range Stratifier":
case
when Patient.ageInYears() between 0 and 20 then 'P0Y--P21Y'
when Patient.ageInYears() between 21 and 40 then 'P21Y--P41Y'
when Patient.ageInYears() > 41 then 'P41Y--P9999Y'
else null
end
The first thing to note here is that this approach involved only a single stratification element to be defined, "Age Range Stratifier", rather than the criteria-based approach, which required defining a stratifier element for each stratification group. Obviouisly, the more stratification groups, the more economical this approach becomes.
Non-subject-based
Non-subject-based, value-based, as an expression
define function "Age Range Stratifier"(encounter Encounter):
case
when Patient.ageInYearsAt(start of encounter.period) between 0 and 20 then 'P0Y--P21Y'
when Patient.ageInYearsAt(start of encounter.period) between 21 and 40 then 'P21Y--P41Y'
when Patient.ageInYearsAt(start of encounter.period) > 41 then 'P41Y--P9999Y'
else null
end
Note that with value-based stratifiers represented as an expression, the expression is written from the perspective of the measure subject, but also defines a parameter with the type of the basis. This is the same approach used to calculate measure observations, because the stratifier expression must be evaluated for each member of the population to determine the stratum value to which that member of the population belongs.
Component Stratifiers
While criteria-based stratifiers are expressed using the stratifier.criteria element, value-based stratifiers are specified using any number of component elements. Each component stratifier specifies an expression that returns the value of the stratifier for members of the population. The advantage of using component stratifiers is that the combinations are computed, rather than having to be expressed. For example, consider the case of stratifying by age-range and gender, for the subject-based example measure:
define "Stratifier P0Y--P21Y":
Patient.ageInYears() between 0 and 20
define "Stratifier P21Y--P41Y":
Patient.ageInYears() between 21 and 40
define "Stratifier P41Y--P9999Y":
Patient.ageInYears() > 41
define "Stratifier Male":
Patient.gender = 'male'
define "Stratifier Female":
Patient.gender = 'female'
Doing this using criteria-based stratifiers is not recommended because it would require specifying a stratifier expression for each possible combination of age range group and gender. With even larger stratifications, this is untenable. Value-based stratifiers simplify this, so you could say:
define "Age Range Stratifier":
case
when Patient.ageInYearsAt(start of Encounter.period) between 0 and 20 then 'P0Y--P21Y'
when Patient.ageInYearsAt(start of Encounter.period) between 21 and 40 then 'P21Y--P41Y'
when Patient.ageInYearsAt(start of Encounter.period) > 41 then 'P41Y--P9999Y'
else null
end
define "Gender Stratifier":
Patient.gender
define "Age Range and Gender Stratifier":
"Age Range Stratifier" + ':' + Coalesce("Gender Stratifier", 'Unknown')
This is better, in that it only requires the creation of a single stratifier element referencing the "Age Range and Gender Stratifier" expression, but it arbitrarily forces construction of stratum values by combining the values from the other stratifiers. Component-based stratifiers allow this to be done directly:
<stratifier>
<component>
<criteria>
<expression value="Age Range Stratifier"/>
</criteria>
</component>
<component>
<criteria>
<expression value="Gender Stratifier"/>
</criteria>
</component>
</stratifier>
When using criteria-based stratifiers, inclusion in multiple strata is possible (i.e. strata are not mutually exclusive). With value-based stratifiers, this means that a given stratifier expression may return a list of values, with each value separately indicating inclusion in a stratum of that value, not that there is a new stratum for a combination of values in the list. For example, a value-based stratifier may return the list of values ['A','B','C']. This indicates inclusion in stratum 'A', stratum 'B', and stratum 'C', separately, not the creation and inclusion in strata 'ABC'.
Using Value Sets for Stratification
It is often the case that the set of possible values for a stratifiers is known and expressible using a terminology. When this is the case, the valueSet element of the stratifier may be used. When this is done, the value set used must be consistent with the other aspects of the stratifier definition. For example, given the "Age Range Stratifier" above, a value set with codes from the "Time Period Ranges" code system can be used to provide the expected possible values as part of the stratifier specification.
Supplemental data represent additional information about a person or population beyond what is included in a core measure specification. Supplemental data often contain information specific to the entity primarily accountable for taking action on the measure results, such as provider-specific variables or those associated with a specific payment system. Supplemental data are descriptive in nature and do not represent an evidence-based quality opportunity, rather they may provide useful additional contextual information about a measure population, or support quality program requirements such as Health IT certification.
Some measure reporting programs, such as the CMS Eligible Clinician Electronic Clinical Quality Measurement program, require specific supplemental data elements (SDEs) to be included in the measure report.
Supplemental data are specified using the supplementalData element of the Measure resource. Like stratifier criteria, supplemental data elements are specified either as a reference to a CQL named expression within a Library or as FHIR resource paths.
For individual-level reports, if the result of evaluating the supplemental data expression for the subject of the report is not a resource, it is reported as a contained Observation resource and included by reference in the supplementalData element of the MeasureReport.
For summary-level reports, supplementalData is reported using contained Observation resources that indicate the number of times each value was encountered as the supplementalData for members of the population. In this case, the code element of the Observation corresponds to the code of the supplementalData, and the component.code element of the observation specifies the supplementalData values encountered, and the component.value[x] element is specified as an integer that represents the number of times that value was encountered in the members of the population.
The CMS146 example measure illustrates the stratification and supplemental data described above:
The data requirements for a measure represent the data of interest as a set of DataRequirement elements. Each data requirement identifies a specific type of data along with constraints that the data must meet. For example, one data requirement for CMS 146 identifies FHIR Condition resources that represent confirmed diagnoses of acute pharyngitis. Other data requirements for this measure include Encounters, DiagnosticReports and other FHIR resources representing specific data that is needed to calculate a valid measure score.
Specifying the data criteria in this way enables the following use cases:
Data criteria can be specified statically, or they can be inferred from the expressions referenced by the measure. The $data-requirements operation can be invoked to retrieve the aggregate data requirements for the measure. This approach has two advantages:
module-definition library.In addition to multiple rate measures, the Measure resource allows for composite measures to be built by referencing existing measures. For example, public health indicators may be defined and combined in multiple ways by different public health agencies:

In the above example, two different agencies are able to make use of the same definitions in different ways by using composite measures.
For a more complete treatment of composite measures, refer to the Quality Measure implementation guide.
FHIR defines both the representation of resources and a general mechanism for interacting with them via the OperationDefinition resource. Prior sections of this topic described the Measure representation of an quality measure, this section describes the $evaluate-measure operation that is used to request the results of calculating a Quality Measure.
FHIR defines a standard set of common interactions that include read, update, delete and search. In addition, FHIR defines a standard set of extended operations that can be performed on resources, resource types and system wide. The standard operations include profile validation, concept translation and value set expansion. FHIR also supports custom operations via the FHIR OperationDefinition resource. This resource offers a means to create a formal definition of a custom operation that can be performed on a FHIR server. For the purposes of measure evaluation we define a new custom operation with a code of $evaluate-measure.
The $evaluate-measure operation has the following properties:
The effect of invoking the $evaluate-measure operation is to calculate the quality measure according to the supplied parameters and to return a MeasureReport resource through which the results will be made available. Note that because measure calculation might not be instantaneous, the MeasureReport resource provides a mechanism to handle long running calculations.
GET [base]/Measure/$evaluate-measure?measure=CMS146&periodStart=2014&periodEnd=2014GET [base]/Measure/CMS146/$evaluate-measure?periodStart=2014&periodEnd=2014The above examples show how to obtain the results of evaluating the measure with id "CMS146" for all patients over a measurement period that consists of all of 2014. Some items of note:
[base]/Measure which is the type of resource and specifies the quality measure to evaluate using a parameter [base]/Measure/CMS146 which is the Measure instance that represents that measure so there's no need to also include a reference to the measure in the operation parametersHTTP GET method is used since the $evaluate-measure operation is idempotent[base] is used as a shortcut for the base URI of the FHIR serverThe next example demonstrates how to obtain the results of evaluating the measure with id "CMS146" for the patient with id "124" over a measurement period that consists of the first three months of 2014.
GET [base]/Basic/CMS146/$evaluate-measure?subject=124&periodStart=2014-01&periodEnd=2014-03The Bundles used in the quality reporting operations enable the evaluation and exchange of data for multiple measures, while also constraining duplicate data. Bundles SHOULD be organized by subject, meaning that a Bundle SHOULD contain the resources, the including MeasureReport(s) and data of interest (in MeasureReport.evaluatedResources), for all of the measures that apply to a single subject. Resources that are not unique to the subject, such as Practitioner or Organization, may still be duplicated across Bundles.
<Organization>
<id value="ad-hoc-organization-example"/>
<contained>
<Practitioner>
<id value="kelly-smith-1"/>
<identifier>
<use value="official"/>
<system value="urn:oid:2.16.840.1.113883.4.4"/>
<value value="EIN-00YYZ"/>
</identifier>
<name>
<family value="Smith"/>
<given value="Kelly"/>
</name>
</Practitioner>
</contained>
<contained>
<PractitionerRole>
<id value="kelly-smith-role"/>
<identifier>
<use value="official"/>
<system value="urn:oid:2.16.840.1.113883.4.4"/>
<value value="EIN-00YYZ"/>
</identifier>
<active value="true"/>
<practitioner>
<reference value="#kelly-smith-1"/>
</practitioner>
<organization>
<reference value="#"/>
</organization>
<code>
<coding>
<system value="http://snomed.info/sct"/>
<code value="133932002"/>
<display value="Caregiver (person)"/>
</coding>
</code>
<specialty>
<coding>
<system value="http://nucc.org/provider-taxonomy"/>
<code value="122300000X"/>
<display value="Dentist"/>
</coding>
</specialty>
</PractitionerRole>
</contained>
<active value="true"/>
<name value="Ad hoc organization example"/>
</Organization>
Implementations SHOULD avoid sending duplicate data (identical FHIR resources or identical resolvable references) in data exchanges ($collect-data or $submit-data) in MeasureReport.evaluatedResources.
Duplicate data is a concern in data exchanges because the operations support multiple measures per subject. The same resource instance could be referenced by multiple MeasureReports, or multiple measures may use different elements within the same resource. Another situation to consider when evaluating a measure is when multiple value sets have overlapping codes, then two different CQL retrieve operations can return the same resource instance because it matches two codes from the overlap.
Note that the $data-requirements operation is currently defined for a single Measure or Library, so it is a responsibility of the data producer to check for, and address, duplicate data.
As described in the section "Bundles Organized by Subject," Bundles utilized in data exchange operations SHOULD be organized by subject. This reduces the potential for proliferation of duplicate data because resources common to the subject, such as Encounters, would not be repeated across Bundles. As described in "Resource URL and Uniqueness rules in a bundle ", a given version of a resource SHALL occur only once in a Bundle, and in data exchange that requires consideration of the data-of-interest and evaluated resources within the Bundle.
Receiving systems need to consider the possibility that some duplicate data may be present across Bundles, such as an Organization resource that is relevant to more than one subject.
The MeasureReport resource represents the results of calculating a measure for a specific subject or group of subjects. The $evaluate operation of the Measure resource is defined to return a MeasureReport. The resource is capable of representing three different levels of report: individual, subject-list, and summary.
A MeasureReport will contain a group for each group specified in the corresponding Measure consisting of a set of population elements, one for each criteria defined in each group. The Measure.group.linkId and Measure.group.population.linkId elements define a linking id that is used to correlate the group and population elements in the MeasureReport back to the corresponding elements in the Measure.
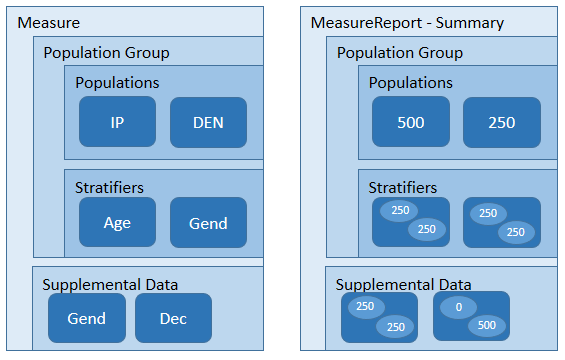
In addition, each group will contain stratifiers with a value stratum for each value defined by the stratifier criteria, for each criteria defined in the measure. The Measure.group.stratifier.linkId element defines a linking id that is used to correlate the stratifier elements in the MeasureReport back to the corresponding elements in the Measure.
When using a MeasureReport resource to represent the results of an individual calculation, the MeasureReport SHALL have a type-code of "individual" and SHALL have a reference to the subject of the report. In addition, the result SHOULD use the evaluatedResource element to include references to any subject-specific resources that were used to calculate the result.
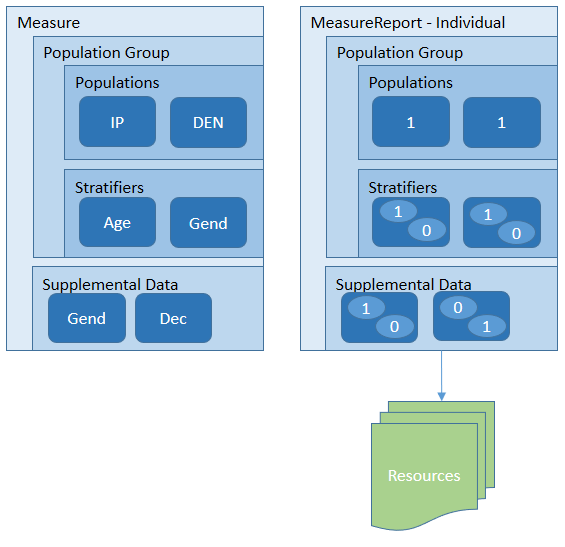
See the MeasureReport examples for a detailed illustration of how the data elements involved in the calculation of the measure are communicated through the evaluatedResources element.
As with population-level reports, the group, population, and stratifier elements have a linkId element that defines a linking id that is used to correlate these elements in the MeasureReport back to the corresponding elements in the Measure.
When using a MeasureReport resource to represent a subject-list, the MeasureReport SHALL have a type-code of "subject-list" and if a subject reference is present, it SHALL be a reference to a Group. In addition, the resource SHALL
MeasureReport.group.population.subjectResults element, a reference to a List resource that references individual-level MeasureReport resources for the same measure, one for each subject instance in the population. For example, the initial population report, in addition to providing the count, provides a reference to a List resource that identifies each of the subjects that make up that population. For each of those subjects, the List will contain a reference to an individual-level report for that subject.MeasureReport.group.population.subjectReport element, references to individual-level MeasureReport resources for the same measure directly.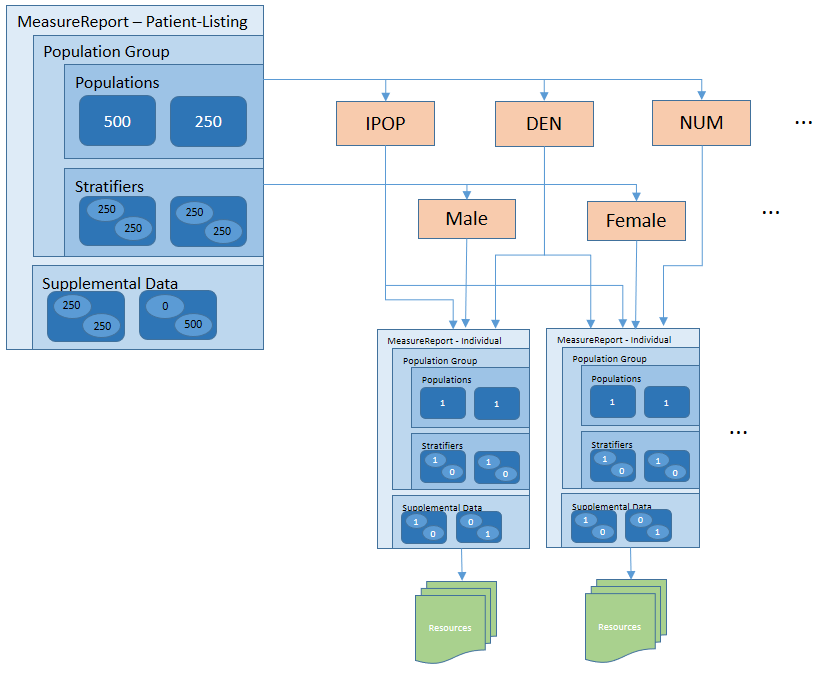
For both options (measure reports provided directly using the subjectReport element or indirectly through a List resource using the subjectResults element), note that for very large populations, implementations MAY decide to limit the size of the result, either by returning an error indicating the request is too costly, or by returning a partial result, so long as there is an indication that the report is only a partial response. In addition, we are actively seeking feedback on how best to approach evaluation of quality measures on large populations, including the use of bulk data formats.
In addition, implementations may return a MeasureReport with a status of pending, indicating that the evaluation is in progress. In this case, clients can request the MeasureReport resource until the status changes to complete.
As part of the evaluation of a Measure to produce a MeasureReport, systems may report information messages, warnings, and errors using the messages element. The messages can be used to reference an OperationOutcome resource describing issues that have occurred during the evaluation. Note that the OperationOutcome resource referenced is typically contained within the returned MeasureReport.
FHIR ®© HL7.org 2011+. FHIR R6 hl7.fhir.core#6.0.0-ballot4 generated on Mon, Jun 15, 2026 01:57+0000.
Links: Search |
Version History |
Contents |
Glossary |
QA |
Compare to R4 |
Compare to R5 |
Compare to Last Ballot |
 |
Propose a change
|
Propose a change