

De-Identification Handbook
2.0.0-comment - ballot
![]()
De-Identification Handbook
2.0.0-comment - ballot
![]()
De-Identification Handbook, published by IHE IT Infrastructure Technical Committee. This guide is not an authorized publication; it is the continuous build for version 2.0.0-comment built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/IHE/ITI.DeIdHandbook/ and changes regularly. See the Directory of published versions
HL7 FHIR (Fast Healthcare Interoperability Resources) is a modern standard for exchanging healthcare information electronically. FHIR uses RESTful APIs and represents healthcare data as modular "resources" such as Patient, Observation, Condition, and MedicationStatement. In secondary use, FHIR data is repurposed beyond direct patient care for research, public health surveillance, quality improvement, and analytics. This involves extracting and de-identifying data while preserving its utility for analysis. Secondary use of FHIR data enables large-scale studies, population health management, and the development of clinical decision support tools, while ensuring compliance with privacy regulations like HIPAA and GDPR.
As shown in the following table, FHIR provides several mechanisms to support de-identification:
Table: FHIR De-identification Mechanisms
| Mechanism | Description |
|---|---|
| Data Absent Reason | Extension to indicate why data is missing (e.g., "masked" for privacy) |
| Security Labels | Meta.security tags to mark de-identification status and handling requirements |
| Redaction | Removal of resource elements containing identifiers |
| Generalization | Replacing precise values with ranges or categories |
| Pseudonymization | Replacing identifiers with consistent pseudonyms to maintain referential integrity |
In this example, we assume a dedicated anonymization service is deployed in an environment serving secondary FHIR data use, which is separated from the environment where the operational EHR system is deployed. The de-identification at the source EHR typically follows basic pseudonymization practices (processing direct identifiers like patient names, contact information, and medical record numbers). In this example, we assume the de-identification behavior can be customized as a pseudonymization policy. Anonymizing the quasi-identifiers, like patient age and geographic location, will be processed by the dedicated anonymization service. The diagram below shows a workflow of the two stages of de-identification.
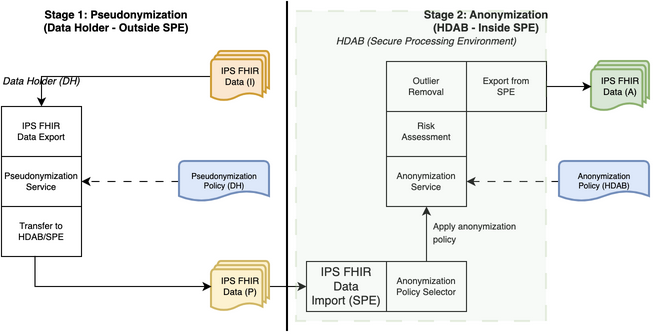
Process Steps: Stage 1
Process Steps: Stage 2
When data elements are removed or masked during de-identification, FHIR provides the Data Absent Reason extension to indicate why the data is not present. This is analogous to DICOM's requirement to set the Patient Identity Removed attribute. Data Absent Reason Codes for De-identification:
| Code | Display | Definition |
|---|---|---|
| masked | Masked | The information is not available due to security, privacy or related reasons |
| unknown | Unknown | The source was asked but does not know the value |
Example Usage:
In the following example, multiple de-identification actions are applied to the Patient resource: Patient.id and Patient.name are pseudonymized, Patient.telecom is removed and marked as masked using the Data Absent Reason extension, and Patient.birthDate is generalized to year-only precision to reduce re-identification risk while preserving analytical value.
Example Patient resource after these de-identification actions:
{
"resourceType": "Patient",
"id": "pseudo-12345",
"meta": {
"security": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationValue",
"code": "PSEUDED",
"display": "Pseudonymized"
}
]
},
"name": [
{
"family": "StudySubject-12345",
"given": ["Pseudo"]
}
],
"telecom": [
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/data-absent-reason",
"valueCode": "masked"
}
]
}
],
"gender": "female",
"birthDate": "1985"
}
For section-level suppression (for example, withholding an entire document section during de-identification), use Composition.section.emptyReason with the List Empty Reason value set, rather than element-level Data Absent Reason.
This is a different mechanism and terminology binding than Data Absent Reason:
| Context | Element | Terminology | Recommended code for de-identification minimization |
|---|---|---|---|
| Element-level missing data | Extension data-absent-reason |
http://hl7.org/fhir/ValueSet/data-absent-reason |
masked |
| Section-level withheld content | Composition.section.emptyReason |
http://hl7.org/fhir/ValueSet/list-empty-reason |
withheld |
When a section is intentionally omitted to satisfy minimum necessary disclosure, set emptyReason to withheld.
Example: Composition section withheld for data minimization
{
"section": [
{
"title": "Social History",
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\">Section content withheld for data minimization.</div>"
},
"entry": [],
"emptyReason": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/list-empty-reason",
"code": "withheld",
"display": "Withheld"
}
],
"text": "Withheld for de-identification and data minimization"
}
}
]
}
FHIR resources should be labeled with appropriate security tags to indicate their de-identification status. This helps downstream systems handle the data appropriately.
Recommended Security Labels:
| Code | System | Display | Use |
|---|---|---|---|
| PSEUDED | http://terminology.hl7.org/CodeSystem/v3-ObservationValue | Pseudonymized | Data with direct identifiers replaced by pseudonyms |
| ANONYED | http://terminology.hl7.org/CodeSystem/v3-ObservationValue | Anonymized | Data processed to remove/transform identifiers to acceptable risk level |
Before De-identification (Identified Data):
{
"resourceType": "Patient",
"id": "patient-12345",
"identifier": [
{
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "MR"
}
]
},
"system": "http://hospital.example.org/mrn",
"value": "MRN123456"
},
{
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "SS"
}
]
},
"system": "http://hl7.org/fhir/sid/us-ssn",
"value": "123-45-6789"
}
],
"name": [
{
"family": "Smith",
"given": ["John", "Robert"]
}
],
"telecom": [
{
"system": "phone",
"value": "+1-555-123-4567",
"use": "home"
},
{
"system": "email",
"value": "john.smith@example.com"
}
],
"gender": "male",
"birthDate": "1985-03-15",
"address": [
{
"line": ["123 Main Street", "Apt 4B"],
"city": "Springfield",
"state": "IL",
"postalCode": "62701",
"country": "US"
}
]
}
After Stage 1 (Pseudonymized Data):
{
"resourceType": "Patient",
"id": "pseudo-a1b2c3d4",
"meta": {
"security": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationValue",
"code": "PSEUDED",
"display": "Pseudonymized"
}
]
},
"identifier": [
{
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "MR"
}
]
},
"system": "http://research.example.org/study-id",
"value": "STUDY-PSEUDO-12345"
}
],
"name": [
{
"family": "StudySubject-a1b2c3d4",
"given": ["Pseudo"]
}
],
"telecom": [
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/data-absent-reason",
"valueCode": "masked"
}
]
}
],
"gender": "male",
"birthDate": "1985-03-15",
"address": [
{
"state": "IL",
"postalCode": "62701",
"country": "US"
}
]
}
After Stage 2 (Anonymized Data):
{
"resourceType": "Patient",
"id": "pseudo-a1b2c3d4",
"meta": {
"security": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationValue",
"code": "ANONYED",
"display": "Anonymized"
}
]
},
"identifier": [
{
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "MR"
}
]
},
"system": "http://research.example.org/study-id",
"value": "STUDY-PSEUDO-12345"
}
],
"name": [
{
"family": "StudySubject-a1b2c3d4",
"given": ["Pseudo"]
}
],
"telecom": [
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/data-absent-reason",
"valueCode": "masked"
}
]
}
],
"gender": "male",
"_birthDate": {
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/data-absent-reason",
"valueCode": "masked"
},
{
"url": "http://example.org/fhir/StructureDefinition/age-range",
"valueString": "35-39"
}
]
},
"address": [
{
"state": "IL",
"postalCode": "627",
"country": "US"
}
]
}
IG © 2021+ IHE IT Infrastructure Technical Committee. Package ihe.iti.deid#2.0.0-comment based on FHIR 4.0.1. Generated 2026-07-14
Links: Table of Contents |
QA Report
| New Issue | Issues
Version History |
![]() |
Propose a change
|
Propose a change