

Clinical Study Protocol
1.0.0-ballot2 - STU 1 Ballot2
![]()
Clinical Study Protocol
1.0.0-ballot2 - STU 1 Ballot2
![]()
Clinical Study Protocol, published by HL7 International / Biomedical Research and Regulation. This guide is not an authorized publication; it is the continuous build for version 1.0.0-ballot2 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/vulcan-udp-ig/ and changes regularly. See the Directory of published versions
| Page standards status: Informative |
The major FHIR elements used are discussed first followed by explanation of the mappings between M11, USDM and FHIR.
We assume a basic understanding of FHIR - to get an introduction, see the section on Introduction to FHIR in the links section of this Implementation Guide.
The elements of FHIR we will refer to are as follows:
Resource - the basic building block defined by the FHIR specification that represents a concept and its key attributes. For our present purposes the key is the ResearchStudy resource.
Datatype - each attribute within a resource has a specific data type. In addition to the usual string, integer etc FHIR also defines complex data types for concepts such as Address, Signature and many more. Of particular relevance is the Code and the CodeableConcept
Terminology - Many items are represented by a fixed Code which represents a specific concept. The human readable representation of the concept is the Term and a code may have multiple different terms to meet conventional wording in a given context but all the terms have the same meaning (concept). Codes can be arranged in a hierarchy and this constitutes a CodeSystem. To express meaning we have to know both the Code and the CodeSystem and for human readability we often include the preferred Term. The Code and the CodeableConcept contain attributes for all three of these elements. To determine which codes are allowed for an attribute we specify a ValueSet which explicitly or implicitly specifies the codes that are allowed. The codes may come from more than one code system. In addition to binding a ValueSet to an attribute we also specify if that ValueSet is the only one that can be used (Required Binding), codes must be used if they cover the concept but new codes can be added for concepts not in the value set (Extensible binding) or the value set is optional (Preferred and Example bindings).
Extensions - FHIR does not attempt to cover all minority concepts but restricts itself to those that are widely used and then provides a mechanism for defining extensions to a resource in a way that existing FHIR servers can handle even though they may never have seen the extension before. To represent the entirety of USDM and M11 concepts we make significant use of extensions.
Profiles - Resources that are defined by the FHIR specification generally have a lot of flexibility in them. For instance:
Profiles are about reducing these options to what is relevant for a particular use case. Attributes that were optional can be made mandatory, allowable codes can be restricted to a small set and so on. Extensions can also be subject to profiling.
The relationship between these components is simplistically shown in the diagram below.
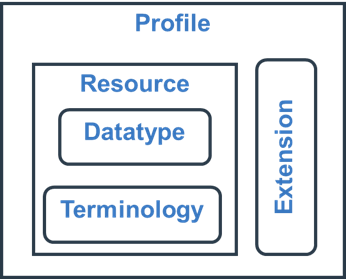
Figure 1: Simple representation of FHIR components
ICH M11 provides a globally harmonized standard set of protocol content and organization of that content through the headings and common text in M11 Template and M11 Guideline. The M11 Technical Specification also provides a bases for digital data exchange by specifying a set of data fields and terminologies to be included in the technical representation of protocols which can be exchanged through various standards. This Implementation Guide specifies how to leverage FHIR for exchange of protocols according to the ICH M11 specifications.
The implementers will vary in their desired use of M11: some will treat as a document, others will leverage structured content, others will utilize for machine processing
The FHIR implementation must therefore cover both narrative and structured content. The challenge is that some data is purely textual while others is quite granular. We also have to recognize that some implementers will cling to a document paradigm while others will want to use the granular machine readable content as they automate systems.
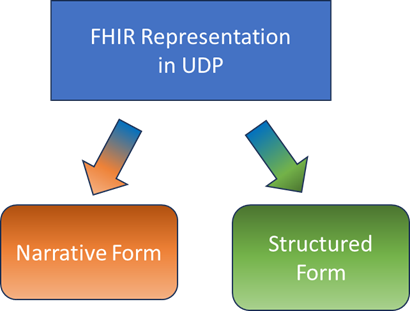
Figure 2: FHIR must support both Narrative and Structured representation
In FHIR representation of "documents" is done using a Composition resource. This is not immediately accessible from the ResearchStudy resource and so we create an extension called NarrativeElements to allow ResearchStudy to point to Composition.

Figure 3: Narrative Elements
To properly reflect the M11 template, the sections and sub-sections in the Composition need to match those in the protocol template.
The template sections can be defined in terminology – a part of the terminology is shown in the diagram below.

Figure 4: A part of the Section Code List (source: NCI Codes listed by M11
Specific narrative instances can then use the codes to specify which parts of the M11 Template they represent.

Figure 5: Narrative Content Example
In the illustration above ResearchStudy has two NarrativeContent sections attached. One with code C218517 which is 1.1.2 Overall Design and one with code C218520 which is 2 INTRODUCTION and this would then have all the sub-sections within the INTRODUCTION.
The structure allows flexibility in the way NarrativeContent compositions are used. It is possible to use a single composition and put all the narrative content into that; at the other extreme it is possible to put every narrative section into its own composition. The expectation is that use of a single composition will be appropriate for document centric use cases but for other use cases where the focus is on more granular data a balance can be found between the number of distinct compositions and the overhead of having multiple compositions.
There are 4 specific examples of allocating parts of the protocol to the Narrative Composition:
| Approach | Description | Instances |
|---|---|---|
| Narrative - Single Composition | Illustration of a protocol with narrative as Single Composition. | ResearchStudy/ResearchStudy-Single-Composition Composition/Narrative-Single-Composition |
| Narrative - Composition per Section | Illustration of a protocol with Composition Section for Each M11 Section | ResearchStudy/ResearchStudy-Composition-Section-Per-Section - Composition/Narrative-Composition-per-M11-Section-1 - Composition/Narrative-Composition-per-M11-Section-2 - Composition/Narrative-Composition-per-M11-Section-3 #- Organization/Narrative-Organization |
| Narrative - Section per Section | Illustration of a protocol with composition for each M11 narrative section | ResearchStudy/ResearchStudy-Narrative-Comp-Per-M11 - Composition/Narrative-Composition-Section-per-Section #- Organization/Narrative-Organization |
| Narrative - Complex | Illustration of a protocol with 1) more granular decomposition of the narrative 2) more complex formatting 3) content that falls outside the M11 template | ResearchStudy/ResearchStudy-Narrative-Complex Composition/Narrative-Complex |
The probable best approach is the second or third of these. The other two examples are for illustration of the options. While none of these approaches carry heavy overheads Implementers need to carefully consider the balance of simplicity and conciseness achieved by using a single composition as opposed to the increased overheads of using multiple compositions.
The real power of a digital protocol comes from representing the content as a series of distinct attributes. USDM and M11 provide information models that can be represented by FHIR using the same resources used for the narrative representation. While many of the necessary attributes are already present there are inevitably some that have no FHIR equivalent. For this we use the extension mechanism.

Figure 6: Structured Content
Some of these extensions are general purpose and will be relevant beyond USDM and M11 and they can be profiled to tie them to exact requirements.
The drawing below shows the names of the Profiles used and the Extensions made for UDP. For description of the function of profiles and extensions see the description above

Figure 7: Profiles of ResearchStudy and Composition and associated Extensions
The list below shows the hierarchy, of profiles, extensions and their attributes (the narrative definitions and amendment definitions should be consulted for the full details)
- p) m11-research-study-profile(ResearchStudy)
- (e) narrative-elements named narrative
- value
- (p) m11-research-study-narratives(composition)
- subject
- section
- type
- author
- (e) M11_ProtocolAmendment named amendment
- scope
- country
- region
- site
- approvalDate
- signature
- signatureUrl
- signatureMethod
- (e) ResearchStudyStudyAmendmentScopeImpact named scopeImpact
- number
- scope
- primaryReason
- secondaryReason
- summary
- substantialImpactSafety
- substantialImpactSafetyComment
- substantialImpactReliability
- substantialImpactReliabilityComment
- (e) ResearchStudyStudyAmendmentDetails
- detail
- rationale
- section
- rationale
- description
- (e) ResearchStudySponsorConfidentialityStatement named confidentialityStatement
- value
The basics of terminology principles are discussed above.
The Value Sets used in this IG are listed on the Artifacts page, in almost every case the value set is composed of terms from the NCI Thesaurus and have been collated by CDISC for ICH and also form part of the USDM work. The values reflect those presented by ICH in the Technical Specification. The exceptions to this are the ISO Country codes and a reference to the one Code System defined here which is for managing the Narrative Element structure.
The following series of diagrams explains how the different models all use a common terminology sourec.
In USDM Phase is represented by the studyPhase attribute of the StudyDesign class.
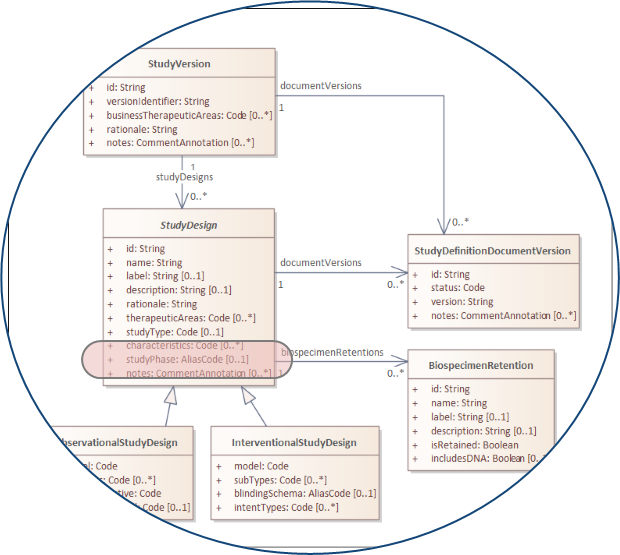
Figure 8 : USDM for "Phase" source: USDM Class Model
In M11 Phase is represented by TrialPhase attribute in the Template and Technical Specification

Figure 9 : M11 for "Phase" source: M11 Template page 2 and M11 Technical Specification page 13/14
These values are all held in the NCI Thesaurus and the concepts are in an NCI code set with code C217045. The images here are taken from the NCI EVS Explore terminology browser at this page.
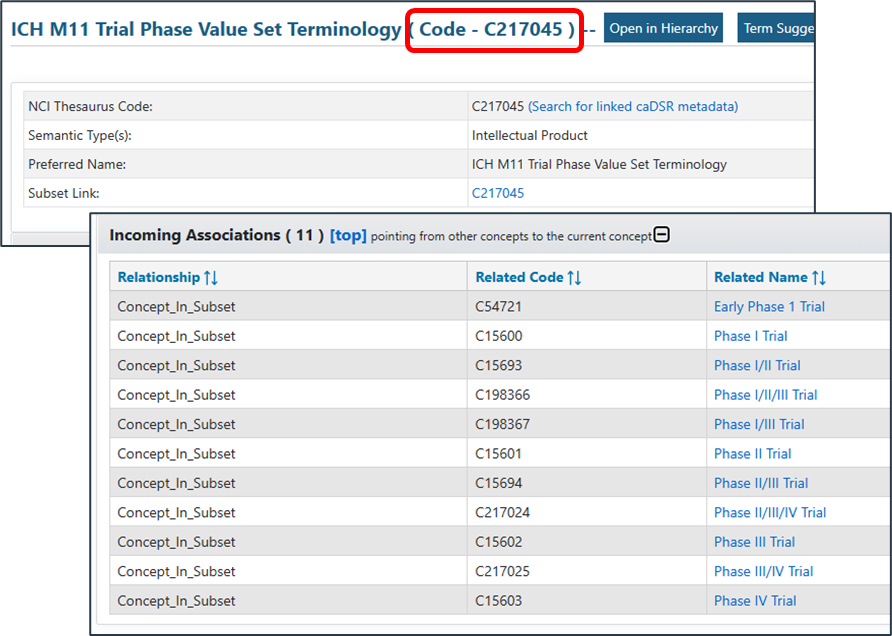
Figure 10 : NCI Code Set for "Phase" source: Screen grab from NCI EVS Explore
In the UDP IG this code set is represented by a value set with the identifier m11-phase-vs and the expansion of the value set is derived from the NCI content (the NCI content is the master, the FHIR value set is not detached from the NCI source).
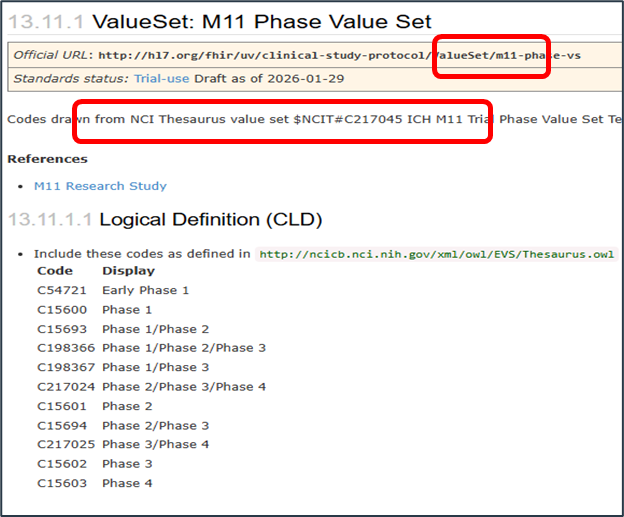
Figure 11 : UDP Value Set for "Phase"
The phase attribute in FHIR is then bound to this value set.
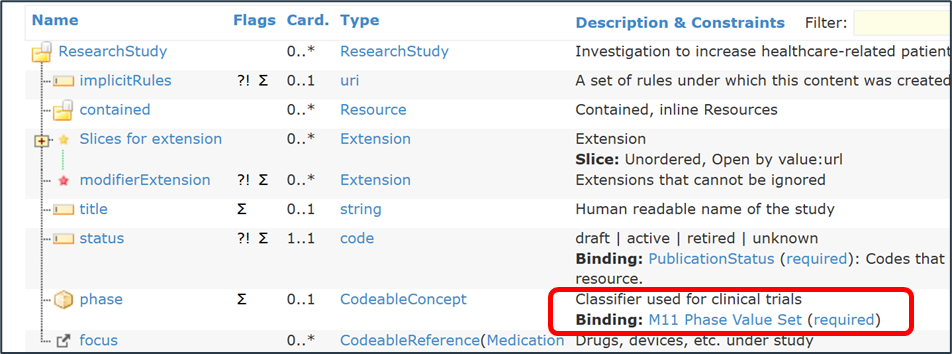
Figure 12: UDP attribute for "Phase" bound to value set
A benefit of FHIR that may not be immediately obvious is that all of the technical content of an FHIR Implementation Guide can be used by a FHIR server to validate content submitted to that server which should comply with the IG. This goes beyond the validation possible for regular JSON or XML content because the IG level validation will only be applied to inputs that say they comply with the IG. This allows a regular FHIR server to perform very targeted validation of incoming content and reject invalid input.
To achieve this level of validation use the Artifact definitions in the Downloads section of this IG and load that content to your server. Your server will have instructions on how to do this.
M11 provides a template for a protocol that defines the sections, sub-sections etc and also a limited number of more granular fields. USDM is not really concerned with the section and sub-sections but instead seeks to represent all of the protocol in granular form. These two approaches have been developed to work in harmony and as a consequence there is an existing mapping from M11 to USDM that keeps concepts aligned.
FHIR exists to provide a uniform method for holding data in a digital form that has an entire infrastructure for validation, storage and transport of data.
There is a new mapping from M11 to FHIR and as noted above there is an existing mapping from M11 to USDM that is provided by CDISC. By extension this combination also provides a mapping from USDM to FHIR.
For many concepts FHIR has some flexibility in how the concept might be represented, not least when codes have to be chosen - there are often different coding systems that might be used. By considering the existing M11 to USDM mapping and selecting a FHIR mapping that is appropriate for both ensures consistency of representation whatever the source.
The usage of the mapping depends on the objective. For a largely document centric approach - for instance protocol approval - use of the mapping will focus on the M11 to FHIR part. In contrast for a data collection tool that seeks to match the data items considered by the protocol to those that the tool will collect the USDM representation is a better starting point. This will require the USDM to FHIR mapping to establish the data representation.
Both M11 and USDM have to converge on the FHIR concepts they map to and so we have to have a three way mapping that relates M11 to USDM and both of them to FHIR.
The relationships between the elements of M11, USDM and FHIR are shown in the Mapping spreadsheet described in the following section. The present focus of this mapping is representation of M11 so the mapping does not cover the whole of USDM. There is a useful infographic from CDISC here: (usdm_m11_classes) that shows the overlap between M11 and USDM and in the bottom right USDM classes not covered by M11.
The spreadsheet for mapping to FHIR is in 3 parts as shown in the illustration. Click on the illustration or click here to download the full spreadsheet
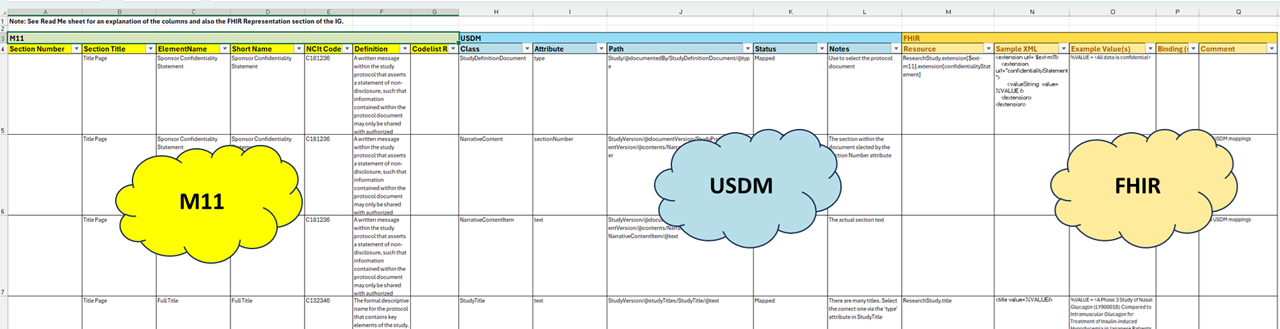
Figure 13: M11 / USDM / FHIR Mapping Spreadsheet
The FHIR columns of the spreadsheet are described in detail below together with examples.
| FHIR Column | Purpose |
|---|---|
| Resource | A simple path to the relevant FHIR resource |
| Sample JSON | A fragment of JSON that illustrates the mapping. |
| Example Value(s) | The key data values represented in the Sample |
| Binding (strength) | FHIR terminology must be bound to a value set and the strength determines whether the value set is fixed or can be extended. |
Narrative Content is noted in the mapping sheet but is shown on a separate tab of the spreadsheet. It is discussed further below.
This is the element in FHIR that maps to the M11 element. In many cases there is a simple equivalent in the standard FHIR resource.
| M11 | FHIR Resource |
|---|---|
| Trial Phase | ResearchStudy.phase |
In other cases there is no immediate equivalent and a FHIR extension has to be used. In the example below the extension is a complex one. Extensions are indicated by the word extension followed by the extension name in square brackets. The extension is called $m11-approval and within that the extension element is called approvalDate. Looking on the Macros page of the spreadsheet shows that $m11-approval expands out to http://hl7.org/fhir/uv/clinical-study-protocol/StructureDefinition/m11-approval
| M11 | FHIR Resource |
|---|---|
| Approval date | ResearchStudy.extension[$m11-approval].extension[approvalDate].valueDate |
The other pattern found is when the ResearchStudy resource points to an instance of another resource for the necessary link. In the example below Sponsor Name is represented in FHIR using an Organization resource which is pointed to by ResearchStudy using the associatedParty element. The reference from one resource to another is shown using -->
| M11 | FHIR Resource |
|---|---|
| Sponsor Name | ResearchStudy.associatedParty.party.reference –> Organization.name.value |
"FHIR Path" is a specific machine processable representation path through a linked series of FHIR resources. That is NOT what is being used here.
For each row the structure is shown in JSON and in a separate cell the key data values are listed.
ResearchStudy.phase is a coded value in FHIR and uses the CodeableConcept data type which itself has multiple elements. Some of these elements have value that is fixed by the mapping and some are the values for the specific instance. In the example below the system value is fixed by the mapping to http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl while the code and display are data items
{ "resourceType": "ResearchStudy",
"phase": {
"coding": [ {
"code": "C15602",
"system": "http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl",
"display": "Phase III Trial" } ] }
These are the variable data items
C15602
Phase III Trial
Amendment Scope is in a separate ResearchStudy resource. The first code block has the reference to ResearchStudy/Exemplar-ResearchStudy-Current-Amendment and the second code block is the ResearchStudy resource with this identifier.
{ "resourceType": "ResearchStudy",
"relatesTo": [ {
"type": "justification",
"targetReference": {
"reference": "ResearchStudy/Exemplar-ResearchStudy-Current-Amendment" } } ],
{ "resourceType": "ResearchStudy",
"id": "Exemplar-ResearchStudy-Current-Amendment", { {
"extension": [
"url": "scope",
"valueCodeableConcept": {
"coding": [ {
"code": "C217026",
"system": "http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl",
"display": "Not Global" } ] } }, ],
"url": "http://hl7.org/fhir/uv/clinical-study-protocol/StructureDefinition/m11-protocol-amendment"
These are the variable data items
C217026
Not Global
{ "resourceType": "ResearchStudy", …
"associatedParty": [ {
"party": {
"reference": "Organization/Exemplar-Sponsor-Organization" },
"role": {
"coding": [ {
"code": "C70793",
"system": "http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl",
"display": "Clinical Study Sponsor" } ] } } ]
{ "resourceType": "Organization",
"id": "Exemplar-Sponsor-Organization",
"name": "Exemplar Pharmaceuticals Co."
These are the variable data items
Exemplar Pharmaceuticals Co.
It happens that the three examples shown here all make use of coded elements but this is not always the case. Binding only applies for coded elements.
For a coded element FHIR requires the specification to state the Value Set of allowed codes. This is important for validation and for ensuring that coded elements conform to a set of values that all will understand. A Value Set can be an arbitrary list of codes (and the identity of the code system they belong to), or the Value Set may specify an entire code system (perhaps with some codes excluded).
The FHIR specification will identify a Value Set of each coded element - this is referred to as the Value Set Binding and these bindings can vary in the extent to which they must be enforced - this is the Binding Strength. Generally a binding on a core FHIR specification can be interpreted quite flexibly and as that core specification is restricted by an Implementation Guide it will become much more rigorously specified. There are 4 Binding Strengths
| Binding Strength | Meaning |
|---|---|
| Example | This value set is for illustration only. It may be useable in practice but no particular effort has been made to ensure that this is so.. |
| Preferred | The bound Value Set is fit for purpose but there may be other equivalent value sets more commonly used in a given context, or there may be different contexts that require a different value set. |
| Extensible | The bound value set has a values that MUST be used for the specific concept they represent - however if other concepts are required a new value set can be created that contains the previously bound value set plus the additional concepts. |
| Required | The Value Set bound to the element is the one that MUST be used. It cannot be replaced, extended or modified. |
As the table above shows the base FHIR specification will generally provide bindings of Example or Preferred strength while an Implementation Guide should provide bindings that are Extensible or Required. Generally if the Value Set refers to a concept that has a limited number of possible values and where adding a value is likely to result in an update to the processing logic (ie a software update) it should be a Required binding. Where an Extensible binding is used processing system should be able to cope with addition of a value - perhaps through an exception mechanism.
The bindings and binding strengths for the examples above are shown below.
$phase-vs (extensible)
$m11-study-amendment-scope-vs (required)
$study-role-vs (extensible)
There are multiple sections that can be represented by Narrative content as discussed earlier. Since these all follow the same pattern the example JSON for the Composition part is shown here:
{ "resourceType": "Composition",
"id": "Exemplar-Narrative",
"meta": {
"profile": [
"http://hl7.org/fhir/uv/clinical-study-protocol/StructureDefinition/m11-research-study-narratives" ] },
"subject": [ {
"reference": "ResearchStudy/Exemplar-ResearchStudy" } ],
"author": [ { "reference": "Organization/Exemplar-Sponsor-Organization" } ],
"section": [ {
"text": {
"status": "additional",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\" xml:lang=\"en\" lang=\"en\"> <h2>1.3 Schedule of Activities</h2><p>Hic textus tantummodo locum tenens est. Nullum verum sensum habet praeter spatium in pagina vel velo implere. Utile tamen est ad rem illustrandam. Huiusmodi ineptiae plerumque cum \\\"lorem ipsum\\\" incipiunt, sed ita translatae non sunt textus laetus.</p></div>" },
"title": "1.3 Schedule of Activities",
"code": {
"coding": [ {
"code": "C218519",
"system": "http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl" } ] } },
The example values here are
C218519
1.3 Schedule of Activities
<h2>1.3 Schedule of Activities</h2><p>Hic textus tantummodo locum tenens est. Nullum verum sensum habet praeter spatium in pagina vel velo implere. Utile tamen est ad rem illustrandam. Huiusmodi ineptiae plerumque cum \\\"lorem ipsum\\\" incipiunt, sed ita translatae non sunt textus laetus.</p>
This implementation guide is based on FHIR Release 6. This release was chosen because of updates to some key resources present in R6 but not in R5. Moving data between FHIR releases is generally feasible by use of profiles and extensions and where necessary "backport" version of an implementation guide can be produced to show how to do this.
During the connectathons held during the development of this IG there has been no demand for a backport version but we have done exploration of what is necessary. Between R6 and R5 the changes are mainly in the ResearchStudy and Group resources. Between R6 and R4 there are additional changes that while manageable take more effort. We are committed to supporting releases of FHIR earlier than R6 if there is a demand. If you have such a requirement please contact the UDP team (udp@HL7Vulcan.org).
IG © 2026+ HL7 International / Biomedical Research and Regulation.
Package hl7.fhir.uv.clinical-study-protocol#1.0.0-ballot2 based on FHIR 6.0.0-ballot3.
Generated
2026-06-22
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change