
Query & Response for Public Health
1.0.0 - ci-build
![]()
Query & Response for Public Health
1.0.0 - ci-build
![]()
Query & Response for Public Health, published by HL7 International / Public Health. This guide is not an authorized publication; it is the continuous build for version 1.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/us-helios-QR/ and changes regularly. See the Directory of published versions
| Page standards status: Informative |
Public health agency FHIR queries involve a two-step process once reportable data is identified in an electronic health system: (1) patient identification and matching followed by (2) a FHIR query to retrieve additional data. First, identify which responders hold data about the patient. If it is already known which organization holds the relevant data, a targeted FHIR query can be used to obtain the FHIR Patient.id. Second, perform a query for supplemental patient information needed to complete the public health agency workflow.
It is understood that QHIN-to-QHIN communication uses IHE-profiled transactions, but QHINs may offer to their participants any number of query mechanisms. Existing implementation guides, such as Mobile Access to Health Documents (MHD), can inform the crosswalk between FHIR and IHE standards.
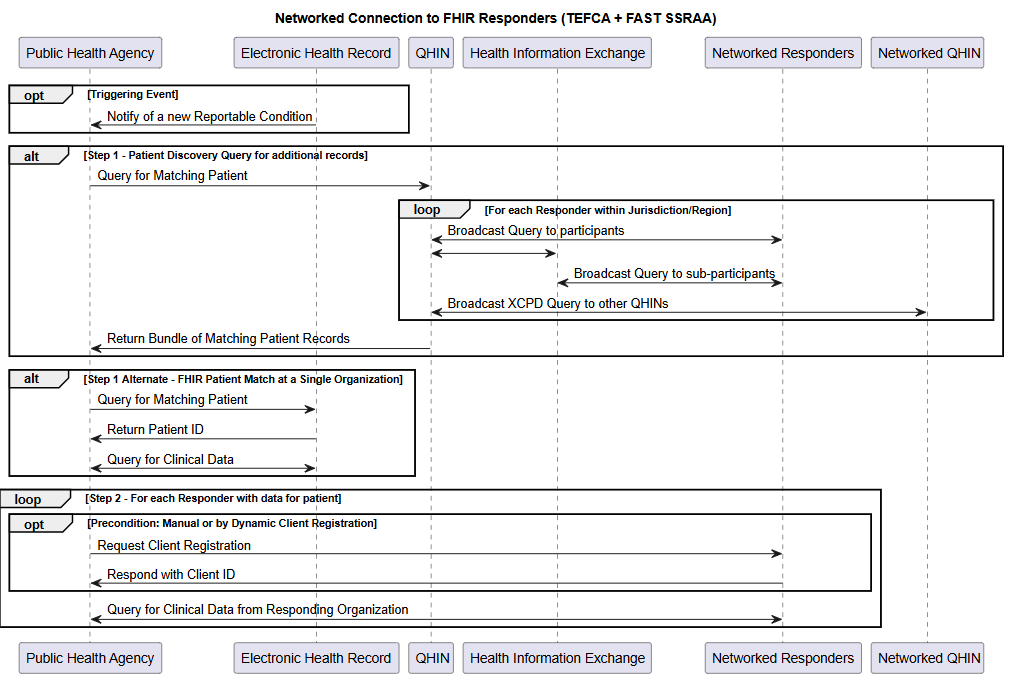
Step 1 (TEFCA Flow): Patient Discovery Query via QHIN
As part of a case investigation use case, a public health agency investigator uses demographic information from an initial Electronic Case Report (eICR), Electronic Lab Report (ELR), or other notification system to compose a Patient Discovery Query. Submitting this Query to the QHIN triggers an ITI-55 Cross Community Patient Discovery Request. Some QHINs support alternative patient search methods, offering Record Locator Services, Master Patient Indexes, or other mechanisms to support patient discovery.
The response to this query includes both the patient identifiers and the Home Community IDs (HCIDs) of the organizations who were able to match the provided demographics. The QHIN’s role is to facilitate connectivity to the FHIR endpoints registered for those HCIDs.
Note: Within TEFCA there is a limitation where only one FHIR endpoint can be represented within an HCID. The guidance in this section is based on that restriction. As facilitated FHIR is being deployed and expanded, this limitation must be addressed to recognize that FHIR endpoints and HCID reflect different data sets and scopes that do not necessarily have a 1:1 relationship. As this limitation is addressed by TEFCA the guidance in this document will adjust further to fully enable FHIR based exchange that is not limited to the scope of document exchange.
Step 1 (Alternate Flow): FHIR Patient Match at a Single Organization
As part of a case investigation use case, a public health agency investigator locates an individual in a provider’s EHR using the Patient search, $match, or $IDI-match operation. The investigator submits a FHIR search for the patient in the EHR using parameters such as the individual’s name, date of birth, and at least one other data element (e.g. phone, street address, email, medical record number, master patient identifier, etc.). Success criteria for the FHIR search is the return of a single high-confidence patient match containing the Patient resource, which provides additional demographic and contact information.
Step 2: FHIR Query for Supplemental information on a Patient
The public health agency investigator submits one or more FHIR queries to the provider EHR (or multiple EHRs) using the FHIR Patient.id retrieved in step 1 above. These queries should be designed to retrieve the minimum necessary data for a given use case. For instance, queries related to Influenza-like Illness should not request lab results related to STI investigations. Using distinct query templates can help case investigators ensure that they receive relevant and useful information in the FHIR response.
Investigators can refine FHIR searches with parameters to narrow results, such as searching for Observations with specific LOINC codes, or Conditions with particular clinical status values. They can combine multiple parameters using AND logic and apply modifiers for more precise matching. Well-constructed searches are essential to ensure only the minimum necessary data is retrieved while still capturing all relevant clinical information.
FHIR offers two primary ways to retrieve resources:
The RESTful nature of FHIR ensures that each interaction is stateless - each interaction or request is self-contained and independent, requiring no memory of previous interactions between the client and server - and complete, with resources being accessed through predictable URL patterns. This facilitates integration across different systems and networks, making it particularly suitable for public health agencies needing to query multiple clinical data sources.
A critical element of implementing FHIR Query and Response is mapping data elements for a particular use case to FHIR Resources. While many data elements will be easily mappable, others, particularly those related to more complex data models or those that are unique to a given use case or program, may be more difficult.
Implementers should start by gathering the functional data element requirements of the end users. Compare these requirements to existing workflows to understand what and how these data are collected; then map these data to FHIR resources.
Not all FHIR Resources or data elements are supported by all HIT products and EHRs. Individual variation in the implementation of an HIT product, such as an organization’s EHR, impacts which data are exposed to FHIR APIs. Not all data elements relevant to a given use case may be available via FHIR RESTful API.
Given the broad support of USCDI data elements across the healthcare space and the related representation of these data elements as profiles in the HL7 FHIR US Core Implementation Guide, public health agency programs are encouraged to begin implementation projects by focusing on data elements contained within USCDI and US Core before attempting to implement a comprehensive FHIR-based strategy. Implementers should also consider USCDI+ data sets and the US Public Health Profiles Library (USPHPL) as relevant resources, however, they should be aware that implementation support for these may be less widespread than that for USCDI and US Core. We also believe that public health agencies will have greater success in expanding the existing suite of widely supported data elements by working collectively with federal authorities and public health associations (e.g., CSTE, ASTHO, NACCHO) to develop standardized data element definitions, rather than by individually making requests of HIT vendors.
IG © 2025+ HL7 International / Public Health.
Package hl7.fhir.us.ph-query#1.0.0 based on FHIR 4.0.1.
Generated
2026-04-23
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change