
Da Vinci Risk Adjustment Implementation Guide
2.1.0 - STU 2.1
![]()
Da Vinci Risk Adjustment Implementation Guide
2.1.0 - STU 2.1
![]()
Da Vinci Risk Adjustment Implementation Guide, published by HL7 International / Clinical Quality Information. This guide is not an authorized publication; it is the continuous build for version 2.1.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/davinci-ra/ and changes regularly. See the Directory of published versions
| Page standards status: Trial-use |
The Da Vinci Project member organizations have identified the need of standardizing how risk adjustment coding gaps are communicated between payers and providers. This implementation guide (IG) specifies standardized risk adjustment coding gap reports and provides guidance to query the coding gap reports from a Payer for one or more patients. Standardizing the reporting structure helps lessen the burden on the providers in processing the reports so they can more easily address the patients’ care needs. This standardized structure also supports the Payer sharing information that they have but the providers may not, such as data from other providers’ claims, lab results, filled prescriptions, etc.
This IG also provides mechanisms enabling the feedback loop from Provider to Payer. Providers may add a Condition Category Remark(s) to the Risk Adjustment Coding Gap Report to indicate that they took some action(s) for a specific coding gap on the report and communicates that back to the Payer. However, if the Provider identifies a coding gap that is on the report needs to be closed or invalidated based on medical record review, this feedback process is done using the Risk Adjustment Data Exchange MeasureReport, which allows the Provider to send the supporting clinical evaluation evidence to the Payer. This feedback loop is important for achieving the goal of improving the accuracy and completeness of risk adjustment.
Figure 2.1-1 shows a high level overview of the risk adjustment workflow, which consists of three main phases: Report Generation, Report Query, and Submit Data to Payer. Detailed guidance for each phase is provided on a separate page under the Methodology section.
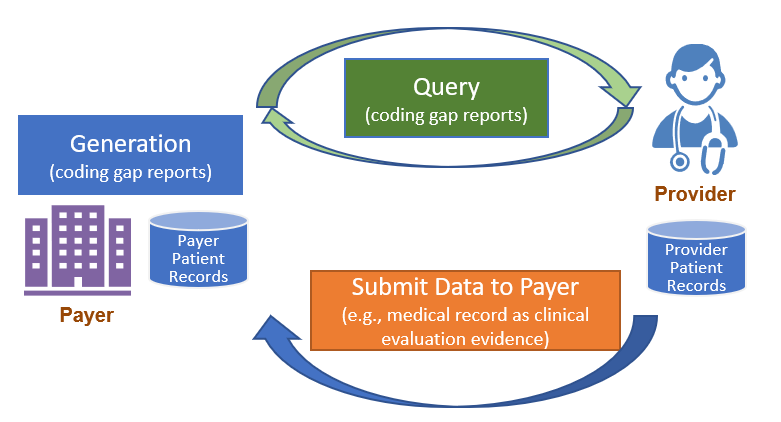
For a complete introduction and background to Report Generation, please visit Report Generation Introduction and Background. Report generation describes two different approaches to generate a Risk Adjustment Coding Gap Report, which are referred to as Assisted and Generated in this IG.
You will find more details on the two approaches at Report Generation Approaches.
The Client can query the Risk Adjustment Coding Gap Report once they are generated. For example, the Payer acting as the Reporting Client can query reports based on search parameters and POST them to the Provider server. See the Report Query page for details and guidance.
Once the queried Risk Adjustment Coding Gap MeasureReports have been sent to the intended recipient, it can be filtered as defined by the EMR and their configuration options to ensure that only germane coding gaps (e.g., HCC gaps) are made available to providers. The Provider (or a software program acting on behalf of the Provider) determines whether the coding gap is currently valid, and whether the requested encounter data evidence exists to close the gap.
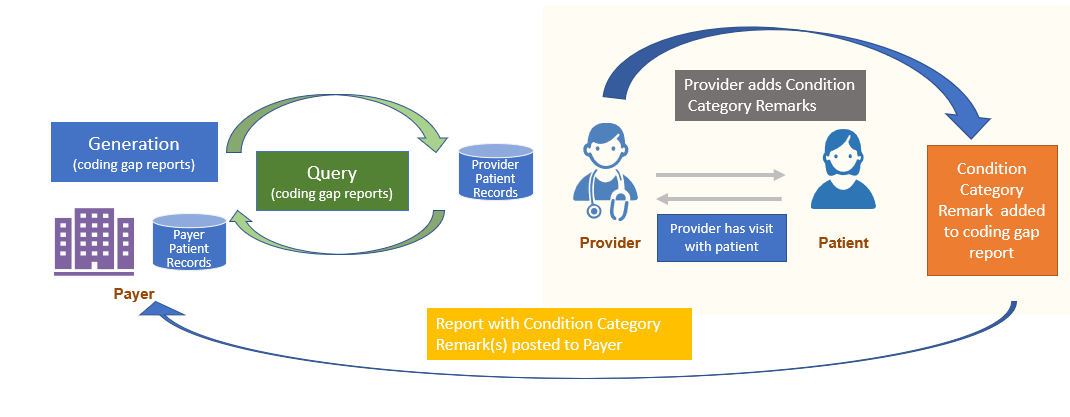
At that time, if the Provider wants to note the action they took regarding a Risk Adjustment coding gap, they can add that comment to the Risk Adjustment Coding Gap Report using the Condition Category Remark extension and return it to the Payer. This process is called Condition Category Remark.
Note: The Condition Category Remark extension is not intended to change the status of a Condition Category gap. To change the coding gap status, follow the Submit Data to Payer section of this guidance. Note that both a Condition Category remark and Submit Data to Payer can be generated at the time the Provider sees the patient if that is appropriate.
To return clinical data, the Provider will use the Risk Adjustment Data Exchange MeasureReport and the $submit-data operation to submit data to Payer. The Payer will then be able to use the provided patient data to update the data in their system that will be included on their next coding gap report generation.
See the Submit Data to Payer page for more details and guidance.
Member attribution establishes associations between providers and payers. The process of establishing and exchanging patient lists for risk adjustment coding gap reports is not in the scope of this implementation guide. One possible way of exchanging Member Attribution Lists between providers and payers is described in the Da Vinci - Member Attribution (ATR) List implementation guide.
Certain elements in the profiles defined in this implementation guide are marked as Must Support. This flag is used to indicate that the element plays a critical role in defining and sharing risk adjustment coding gaps, and implementations SHALL understand and process the element.
This implementation guide uses US Core profiles where appropriate, therefore, the implications of the Must Support flag for US Core profiles must also be considered.
For more information, see the definition of Must Support in the base FHIR specification.
IG © 2021+ HL7 International / Clinical Quality Information. Package hl7.fhir.us.davinci-ra#2.1.0 based on FHIR 4.0.1. Generated 2026-01-08
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change