
Chronic Disease Surveillance
0.1.0 - CI Build
![]()
Chronic Disease Surveillance
0.1.0 - CI Build
![]()
Chronic Disease Surveillance, published by Clinical Quality Framework. This guide is not an authorized publication; it is the continuous build for version 0.1.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/cqframework/aphl-chronic-ig/ and changes regularly. See the Directory of published versions
The proposed scenario will demonstrate the evaluation of Clinical Quality Measures specified in FHIR and CQL that are relevant to chronic disease against a sample population, periodically reporting the results of that evaluation to a central surveillance repository, and viewing the results of that surveillance activity.
The scenario will have two EHR stand-ins (EHR), a stand-in for a central surveillance repository (PHA), and a web-app that allows the searching and viewing of the reported content (Viewer). Each of the EHRs will play the roles of EHR, Reporting Services application, and Trust Services application based on existing open source technology, providing the ability to evaluate CQL, as well as coordinate data submission and the use of trust services. Each EHR stand-in will be loaded with the necessary content (CQL, FHIR ValueSets, etc.) to evaluate the CMS Diabetes (CMS-122) and Blood Pressure (CMS-165) Measures, including sample populations such that the evaluation of those Measures gives a representative result as a FHIR MeasureReport. The Measures will be evaluated on each EHR, and the results of that evaluation will be sent to the PHA. The PHA will expose FHIR-base APIs for searching and reading MeasureReports. The Viewer application with be able to access the PHA's FHIR APIs, and a User will be able to view the collected data within the Viewer application. A high-level diagram of this scenario is below:
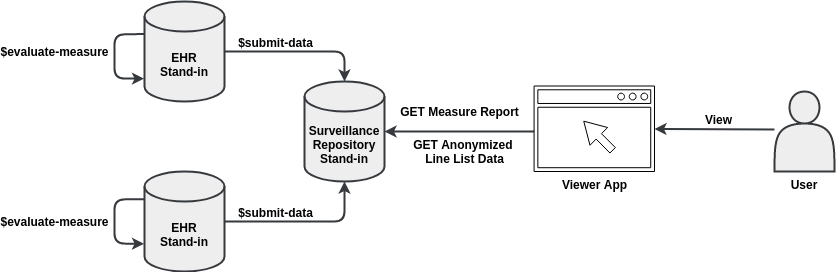
The approximate sequence of events for the scenario is as follows:

The EHR stand-in will need to implement two main areas of functionality:
The $evaluate-measure operation is defined in FHIR's clinical reasoning module. At its core it's the ability to evaluate CQL against FHIR Resources. A FHIR-native repository may have this functionality built in, or it could be provided by a side-car / frontend application connected to a non-FHIR repository (similar in design to the eCR Now application).
The level of effort to add the $evaluate-measure functionality depends on the specific technology choices. There are both open-source and commercial servers available that could be stood up quickly to provide the $evaluate-measure functionality "out of the box". Adding this functionality to a side-car / frontend application may be a bit more involved. There are open-source CQL evaluation engines available for Java and Javascript environments to support that effort.
NOTE: An alternate design here is to create a separate Knowledge Repository in which the Measures and supporting artifacts live. The EHR or side-car / frontend application could use the $data-requirements operations to gather only the data needed for the evaluation of a specific Measure and / or download the logic artifacts.
The EHR stand-in will need to be able run the workflow defined by the sequence diagram above. Specifically, it'll need to run $evaluate-measure for the CMS-165 and CMS-122 Measures, collect the results of that evaluation, and submit that data to the Surveillance Repository.
The Electronic Case Reporting (eCR) IG has parallel needs and uses a PlanDefinition resource to represent its workflow. We propose this scenario represent its logic in the same way. There's no complete open-source or commercial implementation of the PlanDefinition functionality required as of the time of this writing, although the eCR Now app and the cqf-ruler both provide some of the necessary components. The implementation could largely be agnostic of the platform to which it's deployed, with the caveat that adapters would be needed for a few things such as a native scheduling service.
The Trust Services component would need to support an operation to de-identify and/or pseudonymize a set of FHIR resources. Psuedonmyization techniques using hashing to preserve non-identifiable case-related data can be incorporated and potentially augmented here in support of the surviellance use case.
The Surveillance Repository has two main areas of functionality:
The $submit-data operation is defined to allow a FHIR-repository to accept a Measure Report and the associated clinical data.
As with $evaluate-data, there are both open-source and commercial FHIR-native repositories available which already implement this functionality that could be stood up in short order. This functionality could also be supported by a side-car / frontend application that exposes the appropriate API.
The level of effort to provide this implementation depends on the specific technology options selected.
Once the generated MeasureReports are submitted to the Surveillance Repository the Viewer app will need to be able to query them. We propose the scenario use the existing FHIR REST API and search parameters for the MeasureReport resource and constraining the functionality of the View application accordingly.
To demonstrate the submission of the MeasureReports to the central PHA was completed, the Viewer app will implement two screens:
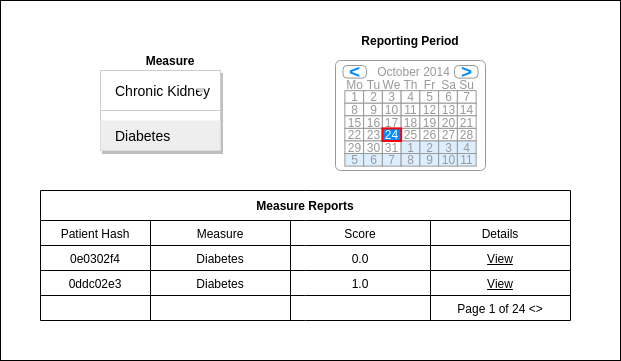
The summary screen will allow the user to select a Measure and Reporting Period, and provide a list of the MeasureReports present. A simple wireframe is below:
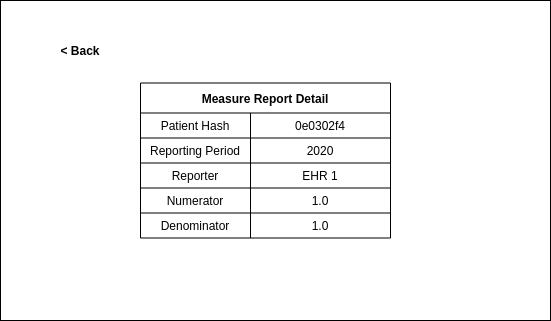
The user can select a MeasureReport from the list and view additional information about it. A simple wireframe is below:
The scenario will use synthetic sample data. The initial implementation will assume that endpoints are open and that authentication is not a concern. However, it will build on existing hash-based pseudonymization capabilities to provide case continuity in submitted data, ensuring that no PHI is present or discoverable from surveillance data.
One consideration would be that it might be useful as part of this project to explore security considerations, in particular how SMART-on-FHIR Backend Services could be leveraged.