

Clinical Document Architecture
2.0.0-sd-ballot - ballot
Clinical Document Architecture
2.0.0-sd-ballot - ballot
Clinical Document Architecture, published by Health Level 7. This guide is not an authorized publication; it is the continuous build for version 2.0.0-sd-ballot built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/ahdis/cda-core-2.0/ and changes regularly. See the Directory of published versions
Introduction
There are an ever-increasing variety of tools and techniques for creating CDA documents:
This appendix considers not the specific tools and technologies, but is intended as a general guide to use of CDA in document creation.
Before you start: RIM compliance
Creating a CDA-compliant instance, by definition, means that the information contained within is defined by the HL7 RIM. Regardless of your starting point or method of document generation, when you are done, the computable semantics of the document will derive their meaning from the relationship between RIM classes, controlled vocabulary and the V3 RIM datatypes. Any CDA-generation implementation must start with an examination of how document requirements relate to the RIM, the datatypes and vocabulary.
The RIM, however, is a highly abstract model and recognizes many extensive vocabulary domains. While RIM-mapping is a necessary condition for CDA generation, it is not sufficient to determine the method of generation or to drive a user interface for document creation.
An exchange specification, not an authoring specification
CDA is a specification for the exchange form of a clinical document. A CDA schema can validate many of the conformance requirements, but will be too general for most authoring applications. In general, standards for interoperability and broadbased exchange will not directly drive an authoring GUI. Given the extent of the CDA domain – clinical care – the requirements for generalized exchange overlap with, but don’t match, the requirements for driving an authoring interface.
For example, the CDA requirement for human readability demands that a single stylesheet render the authenticated clinical content of any CDA document. If CDA elements were defined in the generic schema that corresponds to the sections of a document, <historyOfPresentIllness> or <Subjective>, for example, a stylesheet would need to recognize each of these tags as section-level tags and render them accordingly. The CDA approach, defining <section> and asserting the type of section through coded vocabulary means that not only is the CDA extensible through the externally-maintained vocabulary domains, but that document designers have the flexibility to create hierarchies of sections and to name and tag them according to local requirements, while maintaining compatibility for the exchange context. Thus, while specific tagging that makes it easier to drive a GUI is fine locally, where practice can be more tightly constrained, CDA needs to take a more general approach.
Both sets of requirements, for authoring and for exchange, should be recognized. Within a defined community of interest, such as a single business enterprise, a professional society or in some cases, local and regional health authorities, there can be tight agreement on the form of a document so that the authoring definitions and the exchange definitions coincide. Unless and until there is universal agreement, there can be no universal exchange unless the diversity of local requirements is acknowledged. This is a long-winded way of saying that CDA will remain a general exchange standard, and other approaches must be available to define data entry and document creation validation requirements.
General approaches: constrain or transform
Given that CDA is not an authoring schema, there are two logical alternatives to creating valid CDA instances.
The first is to add constraints to the CDA schema so that the resulting specification defines a particular document type (see the following exhibit “Creating a CDA through a local schema”). There are several technologies available for adding constraints. One approach is to modify the CDA schema itself to a local variant (local.cda.xsd below). Modifications could include limiting the levels of nesting; constraining vocabulary and sequence, for example requiring that a section with a LOINC code for “Subjective” initiate the document body and be followed by a section coded “Objective”. These modifications could be expressed in W3C Schema or as Xpath statements within the local schema. Instances that validate against this constrained, local version of CDA are, by definition, also valid CDA instances.
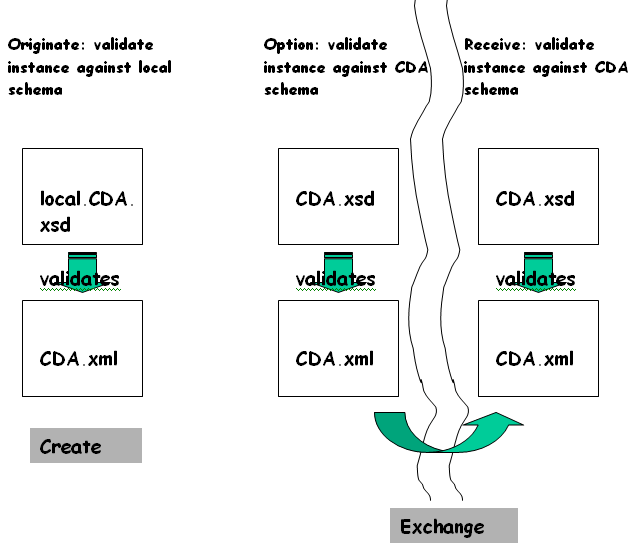
Templates are one type of constraint. HL7 is in the process of defining a formal template mechanism (see The “A” in “CDA”).
The second approach is to create a local schema and then transform the local XML instance to CDA
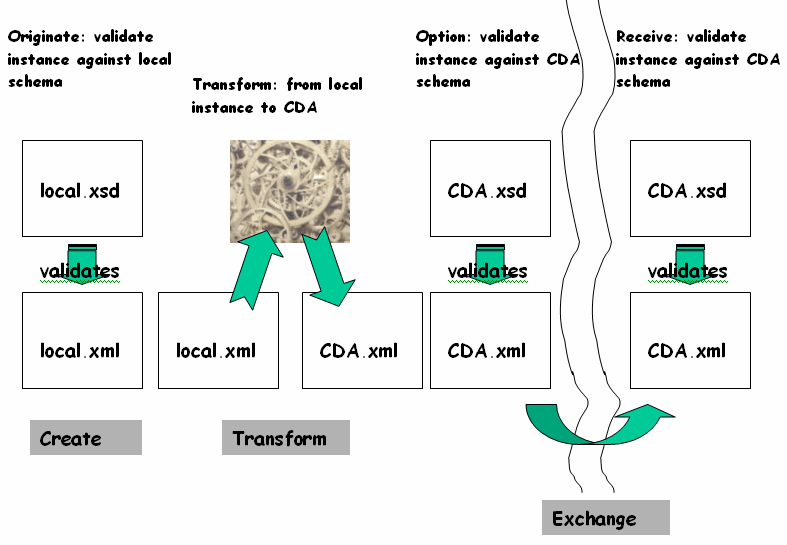
A long term objective of CDA and other specifications in the V3 family is to achieve increasingly greater and greater “semantic interoperability”, which might be defined as the ability of two applications to share data, with no prior negotiations, such that decision support within each application continues to function reliably when processed against the received data.
CDA seeks to achieve the highest level of constraint that can exist in an international standard. Where international consensus is lacking, and where uses cases in different realms currently preclude consensus, CDA will need to be necessarily inclusive. In such areas, ongoing harmonization and consensus building will further enable semantic interoperability, which will be reflected in future iterations of CDA.
While the framework provided by the RIM and by CDA and by the shared HL7 Clinical Statement Model are a critical component of semantic interoperability, they are not currently sufficient, particularly given the lack of global terminology solution, and the fact that each terminology overlaps with the RIM in different ways. Such terminology solutions are outside the scope of CDA, and will need to be addressed in various national and international forums.
IG © 2019+ Health Level 7. Package hl7.cda.uv.core#2.0.0-sd-ballot based on FHIR 5.0.0. Generated 2024-03-04
Links: Table of Contents |
QA Report
| Version History  |
|
 |
Propose a change
|
Propose a change