
Bulk Retrieval of Public Health Data
2.0.0 - Informative 2
![]()
Bulk Retrieval of Public Health Data
2.0.0 - Informative 2
![]()
Bulk Retrieval of Public Health Data, published by HL7 International / Public Health. This guide is not an authorized publication; it is the continuous build for version 2.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/us-helios-bulk/ and changes regularly. See the Directory of published versions
| Page standards status: Informative |
The FHIR Bulk Data Access Implementation Guide (referred to as the Bulk Data IG) was developed and published by the SMART Health IT project at Boston Children’s Hospital Computational Health Informatics Program. This standard addresses the need to efficiently access large volumes of information on groups of individuals. As of the time of publication of this document, the latest version of the implementation guide is version 2.0.0. All efforts undertaken by the Helios Bulk Data Priority Area have focused on this version of the standard.
According to the Bulk Data Export Operation Request Flow section of the Bulk Data IG, a bulk data exchange typically involves two primary roles: the Bulk Data Server and the Bulk Data Client. For a detailed description of the system interactions involved, refer to the Request Flow section mentioned above. In this document, we will refer to this sequence of interactions as the “bulk data query.” For the primary immunization use case discussed here, the Immunization Information System (IIS) implemented by the jurisdictional immunization program serves as the Bulk Data Provider (or Server), while the system used by the Authorized User acts as the Bulk Data Client. In many examples where the Authorized User is a healthcare provider, the system in use is expected to be an electronic health record (EHR), although other types of systems may be employed. We expect that the technical and workflow requirements will be substantially similar across all types of Authorized Users.
The Bulk Data IG defines three approaches to querying data through custom operations:
For the immunization use case, the Bulk Data Priority Area primarily explored the Group Level Export operation, which forms the basis for much of this document. The System Level Export operation was too broad for this use case. Additionally, the concept of cohorts of individuals appropriate for sharing with a given Authorized User rendered the Patient Level Export operation similarly unsuitable. While the Patient Level Export does offer an experimental patient parameter that allows the client to specify a list of patient records to include in the response, Priority Area members felt that the potentially large size of the cohort could pose challenges for this operation. Therefore, focusing on the Group Level Export operation is more likely to yield productive results.
The FHIR Group resource represents a defined collection of entities that may be discussed or acted upon collectively. For the immunization use case, the Group resource serves as a mechanism to identify a cohort of individuals for a bulk data query. The Group resource can be utilized in two ways:
The Group Types section of this document further describes the possible applications for both methods of use. Note that the individuals listed within the Group are references to Patient resources stored on the same FHIR Server as the Group itself.
Each of the three operations in the Bulk Data IG defines a set of input parameters that specify the output of the query response. Below are a few important input parameters for the Group Level Export operation, based on our exploration for pilot and production implementations. Readers should consult the Bulk Data IG for a complete description of all possible parameters for each of the three export operations.
The _since parameter may be important for retrieving data on individuals over time. When querying a cohort multiple times over an extended period, including the _since parameter allows the exchange of only the data that has changed since the last query. By setting this parameter to the date and time of the last query, the system can significantly reduce the volume of data transferred, limiting it to just the changes since the previous query. This reduces the burden on both the server supplying the data and the client processing it.
The _type parameter ensures that Authorized Users receive only the data types they are interested in and eligible to access. In the immunization use case, this may be less critical due to the focused nature of the IIS (see the Data Payload section for details on the resources likely to be exchanged), but it may play a larger role in other public health scenarios where the data source encompasses a broader range of information.
The use of the patient parameter is expected to be limited to specific use cases where the cohort size is relatively small, making it feasible to include an enumerated list of individuals in the bulk data query.
Any interoperability implementation must carefully consider the security and privacy implications of data sharing, and the bulk exchange of public health information is no exception. While this document does not explicitly outline security expectations for FHIR bulk data exchange, it strongly encourages implementers to establish appropriate access controls to ensure adequate data protection. For immunization-specific use cases, providers may model their FHIR access controls on existing controls used for HL7 V2 messaging, influenced by local regulations and policies.
The FHIR base standard explicitly states that it is not a security protocol. Instead, it emphasizes that FHIR-based exchange protocols must be used in conjunction with various security protocols documented outside the FHIR base standard. The Bulk Data IG recommends that providers implementing bulk data utilize OAuth 2.0 access management in accordance with the SMART Backend Services Authorization Profile. For further information on security expectations, please refer to the FHIR Security section of the base standard.
Support for the FHIR standard can be implemented in various ways. Implementers of a bulk data solution for public health use cases should carefully consider their chosen technical architecture. This document aims to provide system architecture guidance for those responding to bulk data queries for immunization history data, such as state immunization programs.
Given the considerable differences in program environments, existing infrastructure, usage volume, and other factors, the Helios effort does not recommend a single "best" architecture. Instead, it shares architectural options and considerations for applying them to specific environments and needs. Implementers developing a solution should assess their organization's existing infrastructure and collaborate with other IT initiatives to implement FHIR locally.
This guidance was developed by a Helios project team tasked with defining how an Immunization Information System (IIS) may need to set up an architecture to support Bulk FHIR queries. The considerations below are informed by the experiences of immunization organizations currently pursuing FHIR capabilities.
Two common approaches for implementing FHIR servers are using a FHIR repository or a FHIR façade. Thorough discussions of both approaches are documented online however a brief overview is provided below.
A FHIR repository is a processing environment (with associated data stores) designed specifically to maintain data as FHIR resources. Data is converted into FHIR format when it is loaded into the FHIR repository.
In contrast, a FHIR façade is a processing environment that maintains data using an internal (non-FHIR) format. Data is converted to FHIR format on-demand when it is requested.
Both patterns can accept both FHIR REST and FHIR Bulk queries and returns FHIR resources.
Note that regardless of the approach selected, programs must consider if/how additional system functionality, such as the evaluation of immunization histories and personalized forecasting of future doses, will be supported as part of responding to FHIR queries. For example, as forecasting functionalities are typically executed on-demand (when a forecast is requested), the use of a FHIR repository strategy must account for how to generate and share these additional FHIR resource types as part of responding to a FHIR-based query. The choice between using a FHIR repository or a FHIR façade involves evaluating the tradeoffs.
Consider a FHIR façade if:
Consider a FHIR repository if:
Implementation considerations related to FHIR repositories and façades include:
The concept of data staging is closely related to the choice between using a repository or a façade, particularly regarding the source of the data used to respond to incoming queries. The immunization data that serves as the source for responses can be managed in various ways. A fundamental decision is whether to use the primary Immunization Information System (IIS) data store or a replica of that data. In other words, will the IIS’s transactional data store be queried directly, or will the query access a copy of the data? If a replica approach is implemented, the frequency of data replication must also be considered: will the replica be updated continuously as the transactional data store is updated (as a parallel mirror), or will it be copied periodically?
Considerations when selecting the method for staging data may include:
Implementation considerations include:
The following section illustrates the relationship between FHIR implementation and data staging concepts. Understanding how these elements interact is essential for developing an effective bulk data exchange strategy. Properly aligning the implementation approach with the chosen data staging method can enhance system performance, ensure data accuracy, and optimize resource utilization.
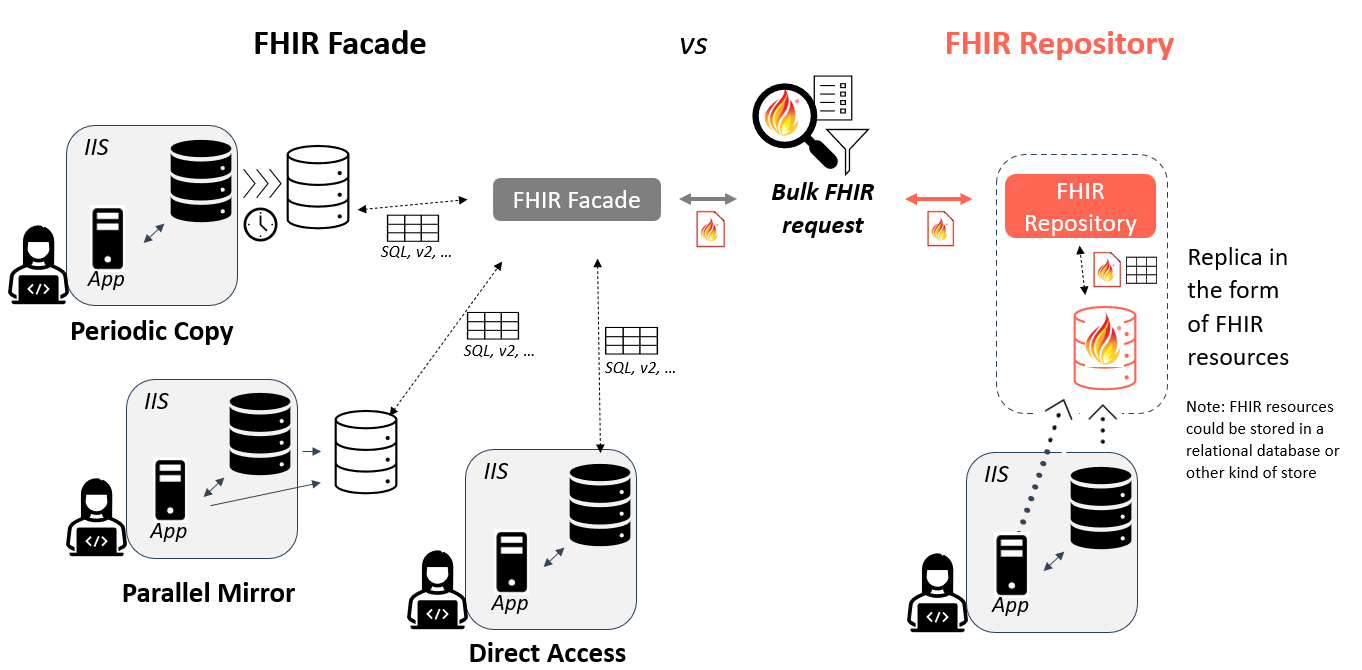
A Group that is the subject of a Bulk Data query may fall into a few categories, depending on how the group is defined and the rate of change among its members. Generally, a group can consist of either an enumerated list of specific individuals for a population of interest or a description of the characteristics of the individuals that make up the population without explicitly listing them.
In the case of enumerated lists, individuals can be added to or removed from the Group as needed, ensuring that the list of relevant individuals is defined at any given time. Conversely, a characteristic-based Group would likely expand to a list of specific individuals only at the time of responding to the query. This "just-in-time" determination may impact query response time, as the responding system must first identify the appropriate individuals that meet the Group's characteristics before retrieving and making the data available. The optimal type of Group will depend heavily on the query's use case and the needs of the trading partners.
A persistent Group consists of a stable list of individuals, where the majority of members remain associated with the Group over time. While new individuals may be added or existing individuals removed, this type of Group is expected to be queried multiple times over an extended period. Example use cases include:
In the "Mechanisms for Patient Identification and Group Creation" section below, several approaches to creating and maintaining persistent Groups are described. While these approaches may allow for the removal of individuals, implementers should regularly review and maintain persistent Groups to ensure that the individuals included remain active and relevant. Without regular reviews, Groups may become bloated over time, negatively impacting system performance and efficiency by inflating data exchanges with unnecessary information.
A transient Group consists of a list of individuals expected to change frequently or to be queried only once. In most cases, the Authorized User is the sole source of information about the Group's content, and the IIS may not have a way to identify individuals to add or remove independently. Example use cases include:
Use cases involving relatively small enumerated transient Groups may also benefit from the Patient Operation, where the experimental patient input parameter specifies a list of Patient resources to include in the response as an alternative to using a Group.
A characteristic Group consists of a set of qualities that describe the members of the Group. Individuals may be included or excluded based on these characteristics, with membership determined dynamically during the response to a query. For example, an Authorized User might create a Group that includes all individuals under a specified age with recorded immunizations residing in a specific zip code, allowing for data exploration without needing to create an enumerated list in advance.
While characteristic-based Groups may be useful for certain scenarios, this document will primarily focus on the use of enumerated Groups for the remainder of the discussion.
Once a Group has been established on the FHIR server for a particular use case serving an Authorized User, the next step is to establish an initial enumerated list of individuals belonging to the Group and to maintain its membership over time. While both Persistent and Transient Groups must be initially established, the maintenance of a Group is more relevant to Persistent Groups. As described in the Mechanisms for Patient Identification and Group Creation section of this document, there are multiple possible approaches to populating and maintaining a list of individuals in a Group. This section outlines general considerations for maintaining a cohort of individuals.
The data payload returned in response to a Bulk Data query can vary. While this document does not specify the exact contents of a bulk query response for the immunization use case, it outlines the resource types that may be included in the response payload. Readers should refer to the Parameters section above for an introduction to the _type parameter, which specifies the response payload.
For queries to an Immunization Information System (IIS) for immunization-related data, expect at least two resource types: Patient and Immunization. These resources together describe the individual and a list of immunization events recorded by the IIS. Responses containing FHIR Patient and Immunization resources represent the immunization history for the set of individuals and may also include related resource types such as Practitioner, Location, Organization, RelatedPerson, ImmunizationRecommendation, and ImmunizationEvaluation to provide a comprehensive view of the patient’s history and context.
To align with existing implementation and regulatory requirements, it is highly recommended to adhere to US Core profiles when responding with data. The specific version of US Core selected may depend on trading partner needs and other FHIR implementations within the public health jurisdiction, but it is advisable to choose a version that complies with health IT regulations.
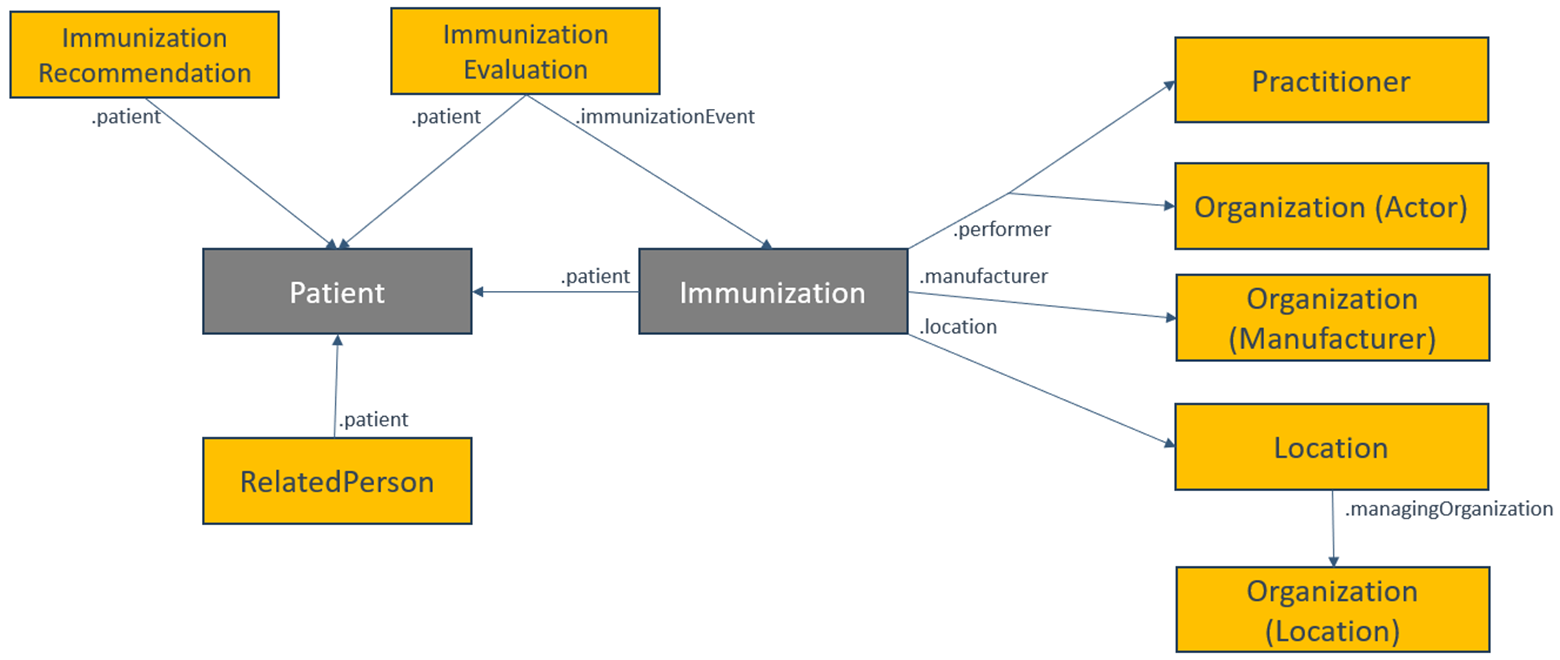
Data exchange partners must agree on the query response payload during the onboarding process to ensure that all data exchanges are appropriate for the involved parties.
IG © 2026+ HL7 International / Public Health.
Package hl7.fhir.us.ph-bulk-data#2.0.0 based on FHIR 4.0.1.
Generated
2026-06-23
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change