
MCC eCare Plan Implementation Guide
1.0.0 - STU1
![]()
MCC eCare Plan Implementation Guide
1.0.0 - STU1
![]()
MCC eCare Plan Implementation Guide, published by HL7 International / Patient Care. This guide is not an authorized publication; it is the continuous build for version 1.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/fhir-us-mcc/ and changes regularly. See the Directory of published versions
The choice in how to package an aggregated CarePlan is dependent on the capabilities of the sender and receiver.
Push from sender to recipient that is expecting only the CarePlan: Push to a system that has an available FHIR server endpoint and which has client architecture capable of following the references within the CarePlan. The sending system carries out a FHIR create, using the HTTP POST request method, that contains the CarePlan. The recipient server then can follow the FHIR references in the CarePlan to find relevant details, such as the CareTeam associated with the CarePlan.
Push from sender to recipient that expects all the relevant details to be included: Push to a system that has an available FHIR server endpoint and which has client architecture capable of following the references within the CarePlan. The sending system creates a FHIR batch or transaction, using the HTTP POST request method, containing the CarePlan and the referenced resources. Note, how deep the referenced resources go is a business level decision.
(Pull) Subscription by recipient: Subscription by FHIR Client that alerts Client to new available CarePlan. Client creates subscription Subscription - FHIR v4.0.1 (hl7.org) using the HTTP POST method. When conditions are met, the client is alerted by the FHIR server that there is new content available. The FHIR Client then retrieves the CarePlan, and any additional referenced resources it needs, using a FHIR API transaction.
Use of Bulk FHIR: For a Bulk Data HL7.FHIR.UV.BULKDATA\Bulk Data IG Home Page - FHIR v4.0.1 FHIR enabled server the client would use the bulk data paradigm to retrieve the CarePlan, and possibly the constituent parts. This is a ‘pull’ by the recipient
The eCare Plan App has been built alongside the IG to demonstrate the principals of the IG in action. It is an example of allowing for patient-mediated exchange of health data as part of care planning. By aggregating care plan data, the standards-based application platform empowers patients and caregivers to actively participate in their care planning for MCC. It enables them to write and share information with their providers, while also providing a comprehensive view of their health data from all providers for goal-oriented care planning. Moreover, the platform supports better care coordination through interoperable data exchange and serves as a companion app to the provider-facing platform, facilitating shared care planning among all members of the care team.
The following figure depicts the types of interactions it performs.
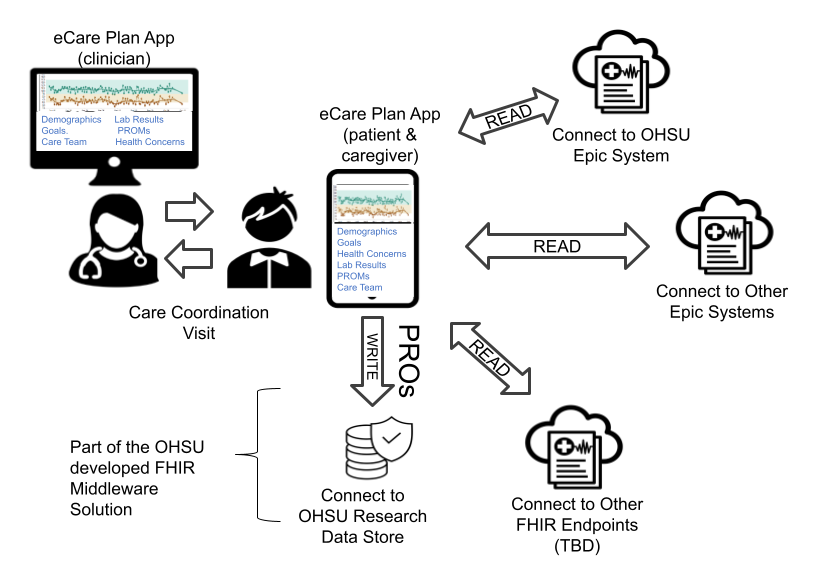 |
The figure below depicts a high-level view of the application aggregating data from multiple sources and then transmitting an aggregated CarePlan to multiple outputs using the FHIR batch transaction interaction through the HTTP POST method.
To aggregate FHIR Careplan instances and care plan data, it's crucial to understand the necessary data for a specific condition. However, the mental model of a care plan varies among providers, systems, and use cases. Sometimes one must look for individual care planning data, in addition to CarePlan instances. Fortunately, there are helpful patterns for aggregating care plan information. The implementation guide defines constraints on key FHIR profiles, emphasizing MUST Support flags to identify essential data elements. It also explains the use of _includes, _revincludes, and other FHIR API features, along with offering use case examples and structure/design considerations. Recall that for a FHIR Careplan the data structure will look something like this diagram. This guidance provides valuable patterns for retrieving and structuring care planning data. Additionally, the effective use of ontologically linked vocabulary is crucial for identifying relevant data to retrieve and structure.
Electronically accessible data in EMRs is associated with codes from standard terminologies. Utilizing these codes enables the retrieval of care planning data. For instance, the condition 'persistent hypertension' can be captured as an ICD10 or SNOMED code from the value set OID:2.16.840.1.113762.1.4.1222.1563. So, to pull relevant FHIR Condition instances one looks for a 'Condition.code' that matches one of the concepts from the value set.
Here is an example FHIR query, using a value set and Condition.code, to search for persistent hypertension as a condition of a patient. The value set is expanded by the server and all Condition instances with a code in the list of codes in the expansion would be returned:
GET [base]/Condition?code:in=http[terminology server base url]/ValueSet/$expand?url=https://vsac.nlm.nih.gov/valueset/2.16.840.1.113762.1.4.1222.1563/
note: if the expansion is too large an error will be returned.
Some systems may not support value set expansions in queries. In such cases, you can adopt an alternative strategy by pulling all Conditions and iteratively looking through them for the Condition.code values one needs.
As an implementer you are looking to find the goal, treatments/procedures and team that is relevant to a specific condition, and then link them as an overall plan for a patient with multiple chronic conditions. To know the vocabulary terms (codes) to use to pull data elements, use our value sets as a starter and iteratively work with the provider systems that treat your patients to determine the value set you need to meet the specific conditions or care of interest.
IG © 2020+ HL7 International / Patient Care. Package hl7.fhir.us.mcc#1.0.0 based on FHIR 4.0.1. Generated 2024-08-13
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change