
FHIR Data Segmentation for Privacy
1.0.0 - trial-use
![]()
FHIR Data Segmentation for Privacy
1.0.0 - trial-use
![]()
FHIR Data Segmentation for Privacy, published by HL7 Security Working Group. This guide is not an authorized publication; it is the continuous build for version 1.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/fhir-security-label-ds4p/ and changes regularly. See the Directory of published versions
This section provides some notes on implementing a Security Labeling System (SLS). These notes are informative and are provided as general guidance and examples; implementers are encouraged to design custom models that are tailored to their workflows and use cases.
The SLS is a software service that determines and assigns security labels to FHIR resources (and in general other types of data objects) based on different types of applicable Labeling Rules that stipulate how data should be labelled. Labeling rules could be rooted in clinical knowledge (e.g., which clinical codes are indicative of substance use treatment), security and privacy policies (e.g., “any record related to substance use treatment should be labelled as restricted”), or other organizational business and workflow rules (e.g., “this information was received from a substance use treatment facility”). A Natural Language Processing (NLP) Service is sometimes necessary to determine the clinical codes implied by unstructured text, and therefore assigning security labels.
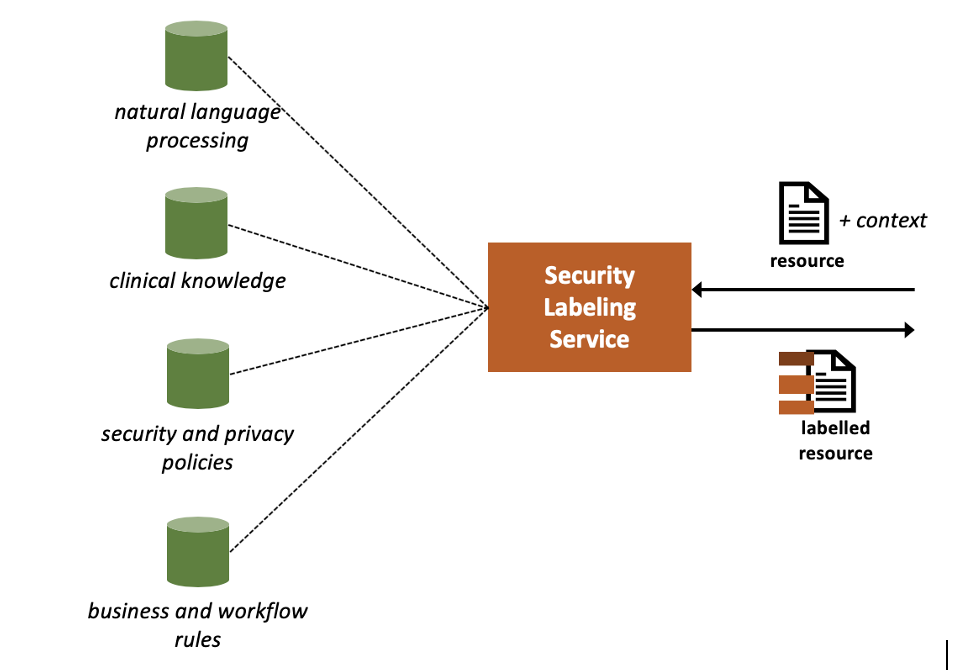
The SLS often provides an Application Programming Interface (API) for assigning labels to FHIR resources. A call to the SLS often includes:
By specifying the type of security labels in its request, the client can control the level of processing involved in the labeling. For example, the client may specify that it is only interested in assigning sensitivity labels. Or, the client may request that the labeling take into account the unstructured text portions of the resource, which would in turn require invoking the NLP module.
The SLS must often be integrated with the rest of the system workflows in order to ensure correct assignment of security labels at the appropriate time, for example, before resources are accessed locally or shared with external requestors. A Security Labeling Orchestrator is the software component that provided this integration logic. Labeling orchestrators are tightly coupled with the business workflows and provide the following functions:
Because of the tight coupling with business workflows, the details of the implementation for labeling orchestrators depend on the use case requirements and the system in which they are integrated. Some of the patterns for implementing the labeling orchestrator are discussed below. Note that most implementations may need a combination of these patterns in order to address all the requirements for their use cases.
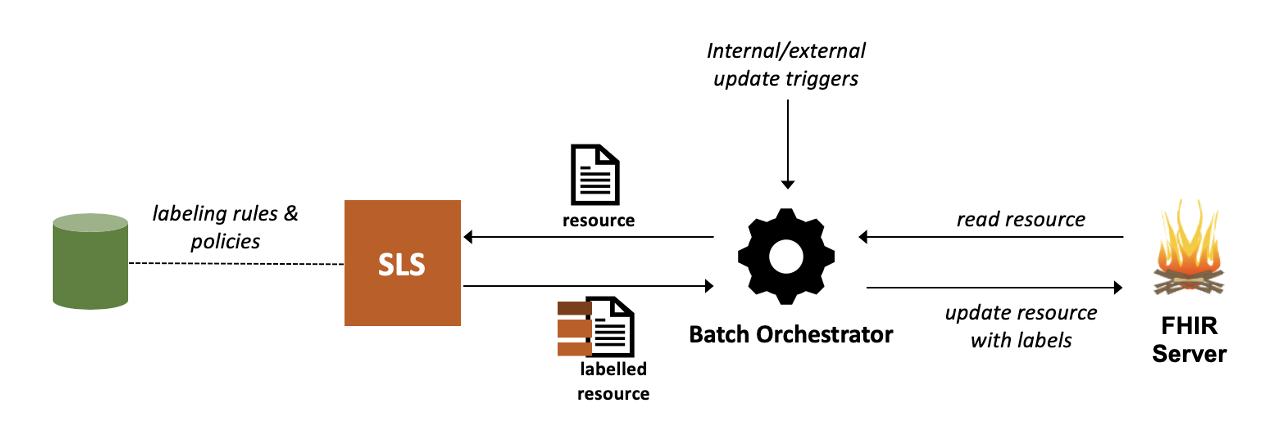
A batch orchestrator submits resources for labeling on an offline basis, either outside of an active transactions, or in the context of an asynchronous transaction such as a bulk data export.
This makes it possible to preemptively label the data (or at least assign some of the labels) and improve the response time at the time of a synchronous transaction.
A batch orchestrator can tolerate longer processing times and asynchronous responses, therefore, it can accommodate more computationally-heavy components such as natural language processing.
On the other hand, since the labeling may take place outside the context of a transaction, some transaction-specific information (e.g., the requester’s attributes or purpose of use) may not be available at the time of labeling in which case labels that depend on such attributes would not be assignable by this type of orchestrator.
Moreover, since labels are assigned and persisted on the resources, the persistence layer of the electronic health records system (e.g., the database) must support the capability to store labels on resources.
Another disadvantage of this method is that in the event of a change in policies and labeling rules, data may need to be relabeled. This usually means that the EHR has to also track a timestamp to record when the labeling has taken place to determine what resources need to be relabeled as a result of a change in rules and policies.
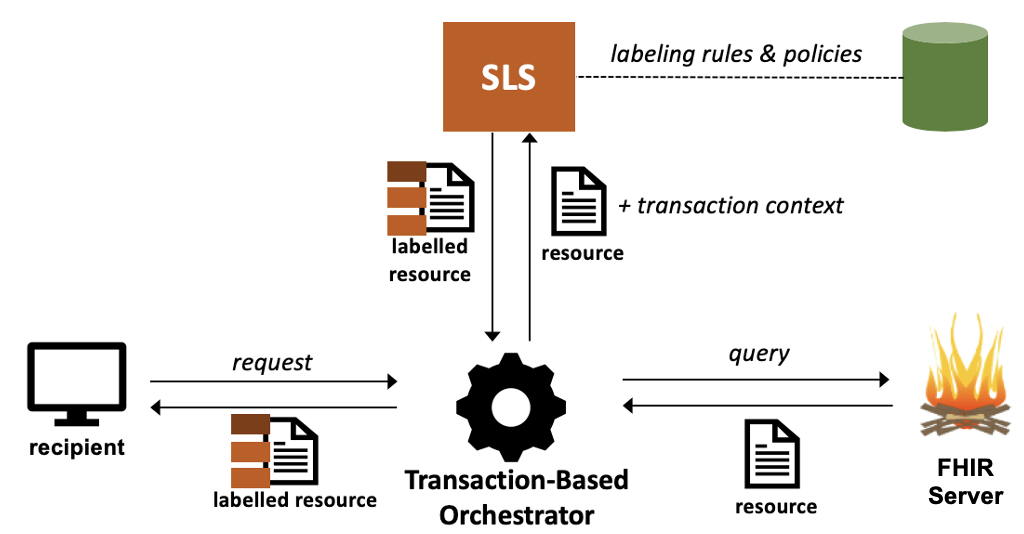
Transaction-Based Orchestrators submit resources to the SLS on-the-fly and in the course of a transaction.
Since this orchestrator is aware of the transaction context (e.g., the identity of the recipient and the purpose of use), it can submit the transaction context metadata to the SLS to enable assigning transaction-dependent labels such as handling caveats.
The dynamic nature of this process also ensures that the most recent versions of policies and rules always drive the labeling at the time of the transaction.
Moreover, this also means that the EHR does not need to support persisting labels on resources which keeps the persistence layer simpler.
On the other hand, since labeling happens synchronously at the time of transaction, the performance overhead may be significant and incorporating computationally-heavy components such as natural language processing may be infeasible.
IG © 2023+ HL7 Security Working Group. Package hl7.fhir.uv.security-label-ds4p#1.0.0 based on FHIR 4.0.1. Generated 2025-05-28
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change