
FHIR to OMOP FHIR IG
1.0.0 - INFORMATIVE 1
![]()
FHIR to OMOP FHIR IG
1.0.0 - INFORMATIVE 1
![]()
FHIR to OMOP FHIR IG, published by HL7 International / Biomedical Research and Regulation. This guide is not an authorized publication; it is the continuous build for version 1.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/fhir-omop-ig/ and changes regularly. See the Directory of published versions
| Official URL: http://hl7.org/fhir/uv/omop/ImplementationGuide/hl7.fhir.uv.omop | Version: 1.0.0 | ||||
| IG Standards status: Informative | Maturity Level: 2 | Computable Name: FHIROMOP | |||
This Implementation Guide establishes a standards-based, community-consensus foundation for transforming FHIR data into the OMOP Common Data Model (CDM). It exists because organizations that need to use both standards — to exchange health data through FHIR and to analyze it through OMOP — have until now had to build and maintain FHIR-to-OMOP transformations independently, producing inconsistent, difficult-to-maintain pipelines that vary from one institution to the next and that frequently diverge in ways that compromise downstream research comparability. By publishing a shared set of transformation principles, mapping patterns, technical artifacts, and best practices, this IG aims to reduce the per-implementation cost and effort of building these pipelines, increase the speed with which new organizations can bring FHIR-sourced data into OMOP, and improve the quality and consistency of the data that results. The guide is deliberately scoped as a primer for FHIR-to-OMOP implementers: it codifies patterns that are already known to work, points implementers to the right OHDSI and HL7 resources for issues that fall outside its scope, and provides a stable base onto which more specialized downstream IGs can build.
The IG focuses exclusively on the FHIR-to-OMOP direction. Prior community work has extensively addressed OMOP-to-FHIR transformation — enabling FHIR API access to existing OMOP repositories — and that direction is covered by other specifications being defined in various HL7 international realms. The gap addressed here is the reverse: moving data that originates on FHIR servers into OMOP-compliant datastores for observational research. The project team generated new guidance only where existing community resources were unavailable, and drew as much as possible from maps and patterns developed in real-world implementations.
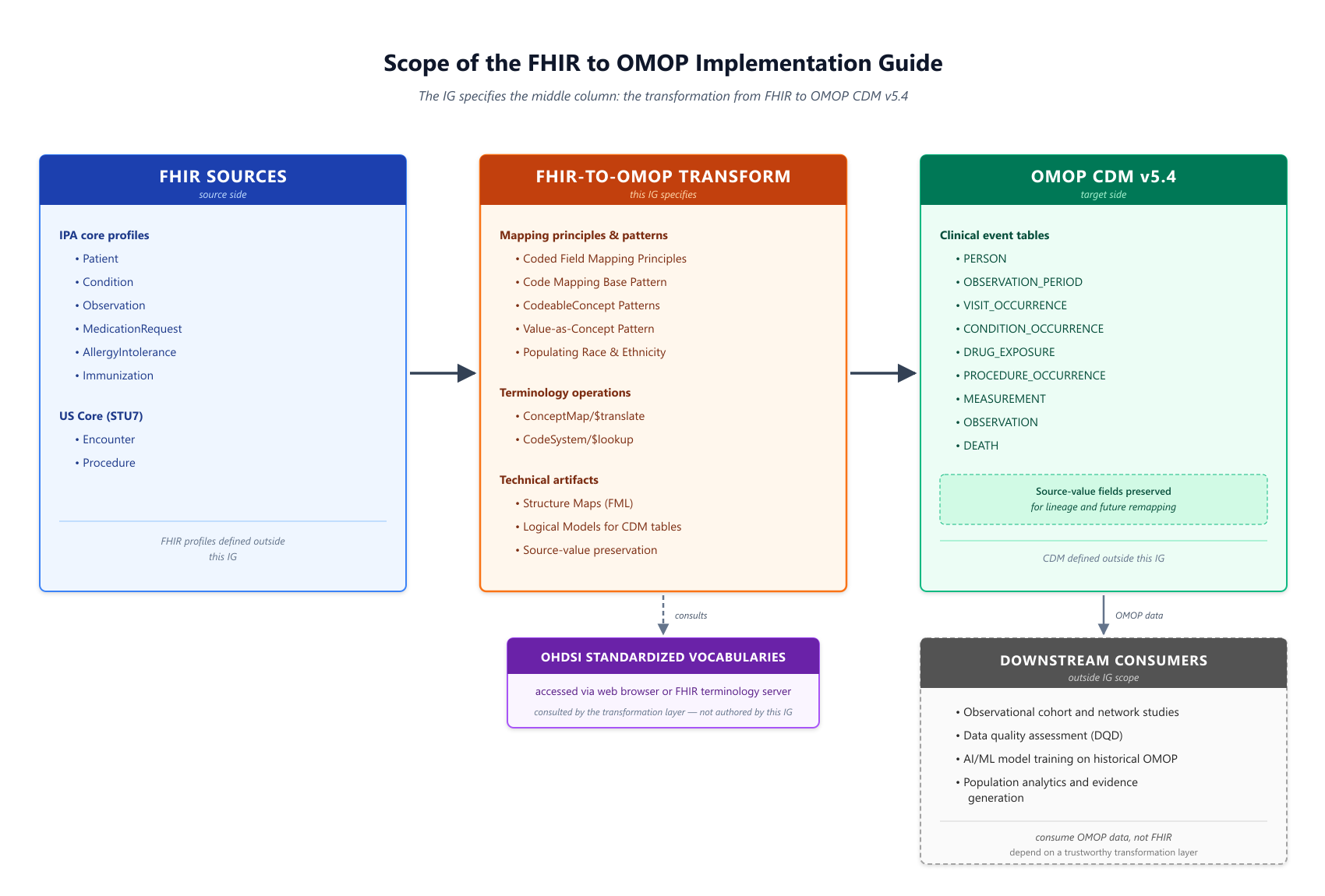
The IG specifies the middle column: the transformation principles, mapping patterns, and technical artifacts that convert a common core of FHIR resources into OMOP CDM v5.4 tables. FHIR source profiles on the left and OMOP target tables on the right are inputs and outputs of the transformation, not defined by this IG. Downstream consumers of the resulting OMOP data — including observational research, data quality assessment, and AI/ML model training — depend on the transformation layer being trustworthy and reproducible, but are outside the IG's scope.
Health care interoperability suffers from what has been described as the interoperability paradox: more standards lead to less interoperability, because each additional standard creates new pairs of systems that cannot communicate without a transformation layer between them [6]. FHIR and OMOP are both open, widely adopted, community-maintained standards, each dominant in its respective domain, and both are likely to remain dominant for the foreseeable future. The practical consequence is that any organization operating across clinical exchange and observational research needs to move data between them routinely. Without a shared transformation specification, every organization doing so solves the problem locally, producing as many FHIR-to-OMOP mappings as there are organizations — each with its own assumptions, omissions, and edge-case handling. Systematic harmonization between standards, in contrast, reduces or eliminates information loss during transformation and allows communities that share data across the FHIR–OMOP boundary to compare analytic results meaningfully [6].
This IG is an application of that harmonization principle to the specific FHIR-to-OMOP pairing. It is not an attempt to replace either standard, nor to suggest that one is superior to the other; both are essential, and the IG treats them as complementary rather than competing specifications.
FHIR and OMOP were designed to serve fundamentally different use cases, and understanding those differences is essential to understanding what this IG can and cannot do. Tsafnat and colleagues [1] describe three distinct domains of health care data, each with its own design requirements:
FHIR is positioned squarely in the data exchange domain. Its RESTful API, resource-oriented structure, and support for rich local terminology reflect a design optimized for moving the right information between the right systems at the right time. FHIR resources are deliberately flexible, permitting variations in how the same clinical reality is expressed — for example, a medication record may appear as a MedicationRequest, MedicationAdministration, MedicationStatement, or MedicationDispense depending on the workflow that produced it — and FHIR does not aim to normalize these variations into a single canonical form [1].
OMOP is positioned squarely in the longitudinal analysis domain. Its relational, patient-centric design and the OHDSI Standardized Vocabularies that accompany it are optimized for large-scale aggregation across heterogeneous data sources, where comparability and reproducibility across sites take precedence over fidelity to any individual source system. OMOP deliberately normalizes local terminology into a small set of Standard concepts within each domain; it uses generalizations (for example, stratifying ages into brackets) that would be inappropriate in an operational exchange context but that are appropriate — and often necessary — for population analytics [1].
Neither design is deficient. Each standard is well-suited to the domain for which it was built. But the designs are not symmetric, and transformations between them cannot be.
The asymmetry between the two standards has direct, practical consequences for what a FHIR-to-OMOP transformation can achieve. Tsafnat and colleagues [6] identify four categories of information loss that occur when transforming data between standards with different design purposes, and all four are routinely encountered in FHIR-to-OMOP work:
Condition carrying a highly specific source code may map to a broader OMOP Standard concept when no equally specific Standard concept exists in the OMOP Condition domain.CONDITION_OCCURRENCE and DRUG_EXPOSURE tables, with the relationship between them recoverable only through inference.MedicationRequest and related resources do not always carry one, requiring the transformation to derive or estimate it from ancillary data.These four loss types explain, concretely, why this IG does not — and cannot — provide a one-to-one, lossless map from every FHIR Resource to an OMOP table and Standard concept. Rather than pretend otherwise, the IG explicitly names these losses where they occur, recommends patterns that minimize them, and requires implementers to document the choices they make so that downstream analysts can interpret the resulting OMOP data correctly. Transformation decisions in this IG favor preserving the clinical meaning of the source data and the analytic utility of the target data over mechanical one-to-one correspondence.
This IG is limited to a common core of EHR data as expressed in the International Patient Access (IPA) IG profile(s). Beyond these core EHR elements, the project team identified a community need to include Encounter and Procedure information to achieve the goal of creating a foundational resource supporting observational research. The IG therefore incorporates the Encounter and Procedures profiles from the US Core FHIR IG (STU7 Sequence) within its scope.
The IG targets OMOP Common Data Model v5.4. At the time this document was developed, v5.4 was the latest version of the OMOP CDM. In 2022, the OHDSI community ceased development of v6.0 because v6.0 made the *_datetime fields mandatory rather than optional, radically changing the assumptions related to exposure and outcome timing. Rather than proceeding with v6.0, CDM v5.4 was designed and released with additions requested by the OHDSI community while retaining the date structure of medical events from v5.3. Detailed changes from CDM v5.3 to v5.4 are available in the OMOP CDM GitHub documentation. New implementations are asked to transform data to CDM v5.4 until the next series of CDM versions is ready for mainstream use [2]. Further detail on the OMOP CDM itself is provided on the OMOP CDM page of this guide.
The IG is deliberately not scoped to:
Although this implementation guide has been developed and tested against FHIR R5, implementers should not consider this a barrier to adoption with other FHIR versions. The core concepts, profiles, and conformance expectations expressed in this guide are intended to be version-agnostic in nature, and there is nothing within this guide that explicitly precludes implementation against FHIR R4 or future versions such as the forthcoming FHIR R6. Implementers wishing to adopt this guide against a different FHIR version are encouraged to review the HL7 FHIR Cross-Version Mapping Pack which provides detailed mappings and guidance for navigating differences between FHIR releases.
[1] Health Level Seven, "Vulcan accelerator home." https://confluence.hl7.org/display/VA (accessed Dec. 08, 2023).
[2] "OMOP Common Data Model." https://ohdsi.github.io/CommonDataModel/index.html (accessed Dec. 08, 2023).
IG © 2023+ HL7 International / Biomedical Research and Regulation.
Package hl7.fhir.uv.omop#1.0.0 based on FHIR 5.0.0.
Generated
2026-06-11
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change