
Making Electronic Data More available for Research and Public Health (MedMorph)
1.0.0 - STU 1
![]()
Making Electronic Data More available for Research and Public Health (MedMorph)
1.0.0 - STU 1
![]()
Making Electronic Data More available for Research and Public Health (MedMorph), published by HL7 International - Public Health Work Group. This is not an authorized publication; it is the continuous build for version 1.0.0). This version is based on the current content of https://github.com/HL7/fhir-medmorph/ and changes regularly. See the Directory of published versions
The following section identifies the business need for each of the initial representative MedMorph use cases:
For Health Care Surveys: Identify and collect hospital (emergency department and inpatient care) and ambulatory care practice data and electronically report these data to a system hosted at the CDC. Electronic reporting should increase the response rate of sampled hospitals and ambulatory health care providers to the National Hospital Care Survey (NHCS) and the National Ambulatory Medical Care Survey (NAMCS). This should also increase the volume, quality, completeness, and timeliness of the data submitted to the NHCS and NAMCS. Automated electronic reporting (without provider involvement) should reduce the burden associated with survey participation and reduce costs associated with recruiting hospital and ambulatory health care providers. Detailed use case, workflows and actors related to the Health Care Surveys use case are documented in the Health Care Survey Reporting IG.
For Hepatitis C: Leverage existing FHIR infrastructure for Electronic Case Reporting (eCR) to improve the availability of data that advance national priorities such as eliminating hepatitis C as a public threat in the US, especially if it becomes a chronic condition when not treated. The goal is to optimize access to hepatitis C data already captured within the Data Source. Detailed use case, workflows and actors related to the use case reportable conditions such as Hepatitis C is documented in the eCR FHIR IG.
For Cancer Registry Reporting: Leverage existing FHIR infrastructure to transmit cancer case information primarily from ambulatory care practices to state cancer registries. The intent is to automate and provide access to data not currently available, or available through non-standard or manual methods, to public health and research. Automation of cancer case registry reporting should reduce the burden of manual or other non-standardized data collection processes that currently exist. The MedMorph cancer registry reporting use case will not replace hospital cancer registry data collection and reporting methods, which are working well. Hospital-based cancer registries use Certified Tumor Registrars (CTRs) to abstract data and maintain information on cancers diagnosed and/or treated in their hospitals. Hospital cancer registries and CTRs follow standardized rules and data collection methods for the purpose of cancer analysis and research – a national standard format and process since 1995. Alternatively, EHR data are primarily used for clinical care and routinely require manipulation and translation to meet the needs of the state cancer registry. The MedMorph cancer registry reporting use case is intended to be used primarily by non-hospital providers (e.g., physician offices, oncology clinics, radiation therapy centers) and by hospitals without cancer registries. Detailed use case, workflows and actors related to the central cancer registry reporting use case is documented in the Central Cancer Registry Reporting FHIR IG.
For Research: Onboard a new research data partner to a research network and contribute data for research. Current processes involve many non-standardized mechanisms. Additionally, each data partner contributing data may use different formats and semantics. For the data to be usable, the data must be transformed to a data model so that it can be queried and analyzed. This process, when standardized, should expedite on-boarding processes and deliver better quality data at a lower cost. Detailed use case, workflows and actors related to the research data exchange use case is documented in the Research Data Exchange IG.
By leveraging FHIR-based APIs, research and public health organizations can automate data collection based on specific events and conditions in clinical workflows and submission of the collected data, complying with all necessary authorities and policies applicable.
This section defines the Actors and Systems that interact within the MedMorph Reference Architecture to realize the capabilities of the use cases listed above.
Data Source (e.g., Electronic Health Record (EHR), Health Information Exchange (HIE), Data Warehouse): Any system that is used in a health care organization to capture, store patient data and make the data available securely with authorized users. The most widely used Data Source is the EHR system, however other systems such as data warehouses, HIE, or registries can also serve as Data Sources. In the MedMorph RA, FHIR APIs will be used to extract data from the data source, process, package the data as needed, and then submit the data to the Data Receiver (e.g., Public Health Agency (PHA) or Research Organization (RO)).
Provider: A person who delivers health care to a patient. In addition to delivering care, the provider also updates patient data and signs off on the content added, deleted, or modified in the patient record once it is updated. The provider can be the individual doctor, nurse, or a combination of different people that are part of the care team.
Knowledge Artifact Repository: Enables the full spectrum of reporting and querying for programs, studies, and initiatives by distributing metadata such as surveys, trigger codes, timing constraints, decision support artifacts, and other knowledge artifacts to:
An example of a Knowledge Artifact Repository is the Association of Public Health Laboratories (APHL) Informatics Messaging Services (AIMS) Platform. The AIMS Platform hosts the Electronic Reporting and Surveillance Distribution (eRSD) Knowledge Artifact used for the eCR program.
Health Data Exchange App (HDEA): A system that resides within the clinical care setting and performs the reporting functions to public health and/or research registries. The HDEA, MedMorph’s backend services app, uses the information supplied by the knowledge artifact repository along with applicable authorities and policies to determine when reporting needs to be done, what data needs to be reported, how the data needs to be reported, and where the data should be reported. The term “backend service” is used to refer to the fact that the system does not require user intervention to perform reporting. The term “app” is used to indicate that it is like a SMART on FHIR App which can be distributed to clinical care via Data Source (e.g., EHR) vendor-specified processes. The Data Source vendor-specified processes enable the HDEA the ability to use the Data Source’s FHIR APIs to access data. The health care organization is responsible for implementing and maintaining the HDEA within the organization.
NOTE: The HDEA functionality can be implemented by EHRs themselves.
Trust Service Provider: Trust Service Provider affords capabilities that can be used to pseudonymize, anonymize, de-identify, hash, or re-link data that is submitted to public health and/or research organizations. These capabilities are called Trust Services. Trust Services are used, when appropriate, by the HDEA.
Trusted Third Party (TTP): A system at an intermediary organization that serves as a conduit to exchange data between health care organizations and a data receiving organization and may perform other intermediary functions (e.g., apply additional business logic) using appropriate authorities and policies. Examples of TTP include Health Information Exchange (HIE), Reportable Condition Knowledge Management System (RCKMS)/Association of Public Health Laboratories (APHL) Informatics Messaging Services (AIMS) Platform). For example, in the eCR use case RCKMS on the AIMS platform is playing a critical compliance role to confirm reportability (i.e., the Reportability Response) in accordance with state laws.
Data Receiver (e.g., PHA, RO): A system that receives and stores the data. A PHA is a government or government-designated organization allowed to receive the data from provider organizations or TTPs using appropriate authorities and policies. PHA may also analyze the data and initiate responses back to health care organizations. For more detailed information on how the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule applies to Public Health, please refer to HIPAA Rules. A RO is an organization that can access the data from clinical care or data marts for research purposes with appropriate data use agreements, authorities, and policies
Data Mart also known as Data Repository: A system receiving the data from the clinical care system. A Data Mart / Data Repository is used to represent systems such as cancer registries, National Health Care Survey data stores, surveillance systems, electronic vital records systems, or research databases. Data Marts are actively managed and are used to receive data, store data, and perform analysis as appropriate. These data marts can be operated or accessed with appropriate authorities and policies (e.g., by a PHA or their designated organizations such as trusted third parties, health care organizations, research organizations)
A Local Data Mart is hosted by the health care organization itself and may be used to support research use cases, reporting use cases, and other analytic capabilities.
A TTP Hosted Data Mart is hosted by a TTP on behalf of a Data Receiver using appropriate authorities and policies.
NOTE: Data Marts can also be hosted by the Data Receiver themselves using the appropriate authorities and policies.
This section outlines the high-level interactions between the various MedMorph Actors and Systems defined above. These interactions are shown in the Figure 3.0 below along with the descriptions for each step.
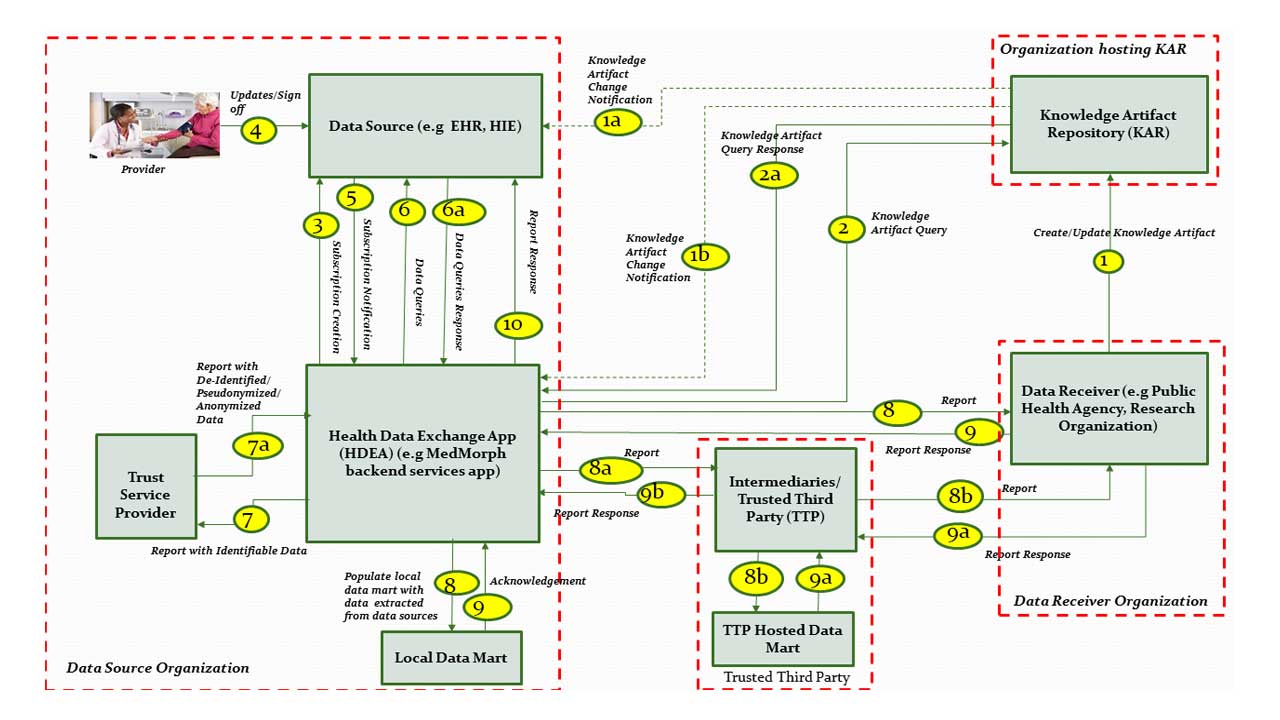
The descriptions for each step in the above diagram are described below:
Step 1: A Data Receiver (e.g., Public Health Agency (PHA) or a Research Organization (RO)) creates a Knowledge Artifact and makes it available via the Knowledge Artifact Repository (KAR).
Step 1a: KAR systems that support notifications, will notify the Data Sources which are subscribed to Knowledge Artifact changes.
Step 1b: KAR systems that support notifications, will notify applications such as Health Data Exchange App (HDEA) which are subscribed to Knowledge Artifact changes.
Step 2: Upon initialization or change notification, the Health Data Exchange App (HDEA) queries the Knowledge Artifact Repository to retrieve a specific Knowledge Artifact.
Step 2a: HDEA receives the Knowledge Artifact as a response to the query in Step 2.
Step 3: HDEA processes the Knowledge Artifact and subscribes to specific events to establish proactive event notifications from a FHIR server. For example, the HDEA subscribes to the Data Source’s FHIR Server so that it can be notified when specific events (as defined in the Knowledge Artifact) occur in clinical workflows.
Step 4: Providers as part of their clinical workflows update data that get reflected in the data source and further lead to notifying the subscribers of specific events.
NOTE: No additional data entry is required by the provider to enable MedMorph RA based reporting.
Step 5: Data Source notifies the HDEA based on subscriptions in Step 3.
Step 6: HDEA queries the Data Source for patient’s data.
Step 6a: HDEA receives the response from the Data Source with the patient’s data.
Step 7: HDEA assembles identifiable data for submission. When necessary HDEA uses the Trust Service Provider to de-identify, anonymize, pseudonymize or hash the data as needed.
Step 7a: HDEA receives the de-identified, anonymized, pseudonymized, or hashed data.
Step 8: The HDEA submits the data assembled as part Steps 7, 7a to a Local Data Mart or an external Data Mart which may be hosted by a Data Receiver directly.
Step 8a: In cases where the Data Receiver requires a TTP to receive data from a Data Source on behalf of them, the HDEA submits the assembled data to the TTP.
Step 8b: The TTP receives the assembled data from HDEA and forwards necessary data to the Data Receiver.
Step 9: In some use cases, the Data Receiver may send a response back to the Data Source based on the submitted data. In some use cases, (e.g Populating a Local Data Mart for research), an acknowledgement may be provided to the submitted data without an actual response. The response transaction may be synchronous (as part of Step 8/8a) or asynchronous (delivered later in response to step 8/8a).
Step 9a: The Data Receiver can require a TTP to act as intermediaries to submit reports to the Data Source on their behalf. For these scenarios, the Data Receiver submits a response to the TTP.
Step 9b: The TTP receives the submitted response from the Data Receiver and forwards the response to the HDEA which is part of the Data Source organization.
Step 10: The HDEA may store the responses locally or forward the response from the Data Receiver to the Data Source as appropriate.
Note: The response may have to be re-identified in some scenarios using Trust Service Provider before it is written back to the Data Source.
The next few sections details the subsets of the above interactions for ease of understanding and documenting detailed interactions using applicable FHIR mechanisms.
The following section outlines each of the MedMorph workflows, actors, and their interactions based on MedMorph Use Cases.
The MedMorph RA starts with the Provisioning Workflow. The provisioning workflow includes creating knowledge artifacts, loading them into a Knowledge Artifact Repository, retrieving the knowledge artifacts to create topics or subscribe to changes in a Data Source. The Provisioning Workflow involves the activities whereby a Data Receiver (e.g., PHA or RO) publishes a Knowledge Artifact(s) specific to a use case. The published Knowledge Artifact(s) is then downloaded by the HDEA. HDEA may subscribe to notifications from the Data Source based on the information within the Knowledge Artifact. The actors and steps from the MedMorph RA that are involved in the Provisioning Workflow are shown in Figure 3.1 below
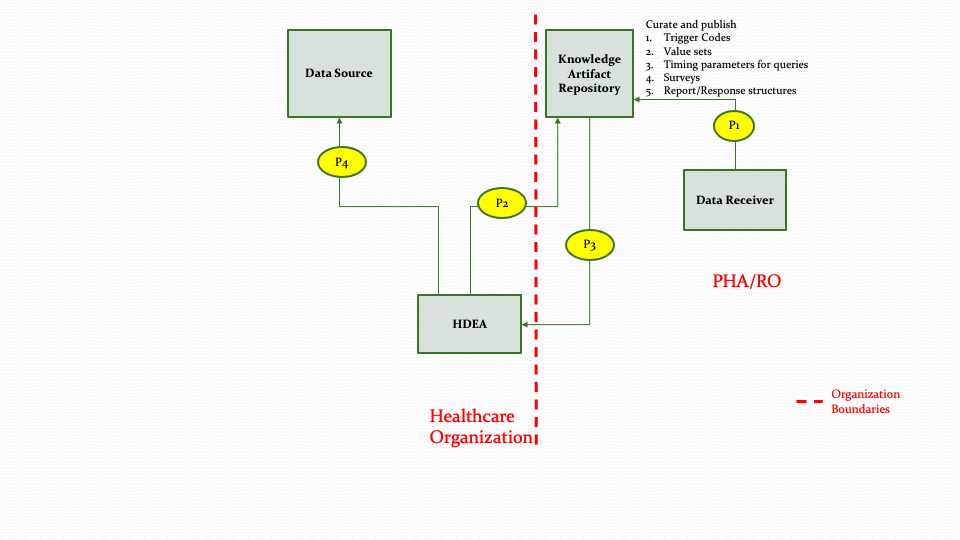
The descriptions for each step in the above diagram are described below:
Step P1: Data Receiver (e.g., PHA/RO) or their authorized designee creates the necessary knowledge artifacts for different reporting/research scenarios and publishes the artifacts in the Knowledge Artifact Repository. These knowledge artifacts may include trigger codes, timing constraints, report definitions, surveys, value sets, etc.
Step P2: The HDEA queries the Knowledge Artifact Repository for the appropriate artifact.
Note: Step P2 could be a result of an out of band notification (e.g., email/sms) that something has changed, or it could be a response to a subscription notification.
Step P3: The HDEA receives the knowledge artifact in response to the query in Step P2.
Step P4: The HDEA subscribes to topics in the Data Source based on the metadata received in Step P3 for reporting.
The Notification Workflow involves the activities whereby a provider, as part of the care delivery process, updates a patient’s medical record within a Data Source. The Data Source, based on the changes to the medical record and existing subscriptions, will notify the HDEA of the changes in the medical record. The HDEA will perform actions such as querying the Data Source for additional data, scheduling a reporting job, or creating a report for submission based on the notification and the Knowledge Artifact information. The actors and steps involved in the workflow are shown in Figure 3.2 below.
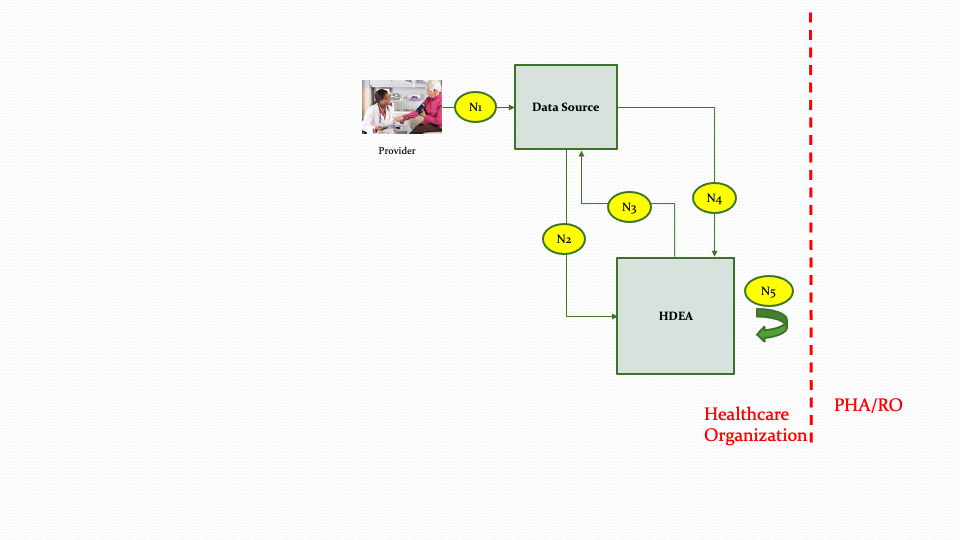
The descriptions for each step in the above diagram are described below:
Step N1: The provider as part of the care delivery process updates the patient record within the Data Source.
Step N2: The Data Source will notify the HDEA about the changes in the patient record based on subscriptions.
Step N3: Upon receiving a notification, the HDEA queries the patient record from the Data Source using FHIR APIs to evaluate if reporting needs to be performed. (The queries executed in this step are only for evaluation purposes and not for creation of the payload for submission).
Step N4: The HDEA receives the data from the Data Source based on the queries in Step N3.
Step N5: Depending on reporting parameters and the data received from the Data Source in Step N4, the HDEA may perform internal processing such as setting up scheduled jobs for reporting at a later time or designating that there is nothing to report.
The Report Creation Workflow involves the activities whereby the HDEA collects the data necessary for creating the report to be submitted to the Data Receiver (e.g., PHA or RO). The HDEA may then perform additional activities such as using a Trust Service Provider for pseudonymization, anonymization, hashing, or de-identification based on the specific use case need defined in the knowledge artifact. Finally, the HDEA assembles the data in the required reporting format for submission. The actors and steps involved in the workflow are shown in Figure 3.3 below.
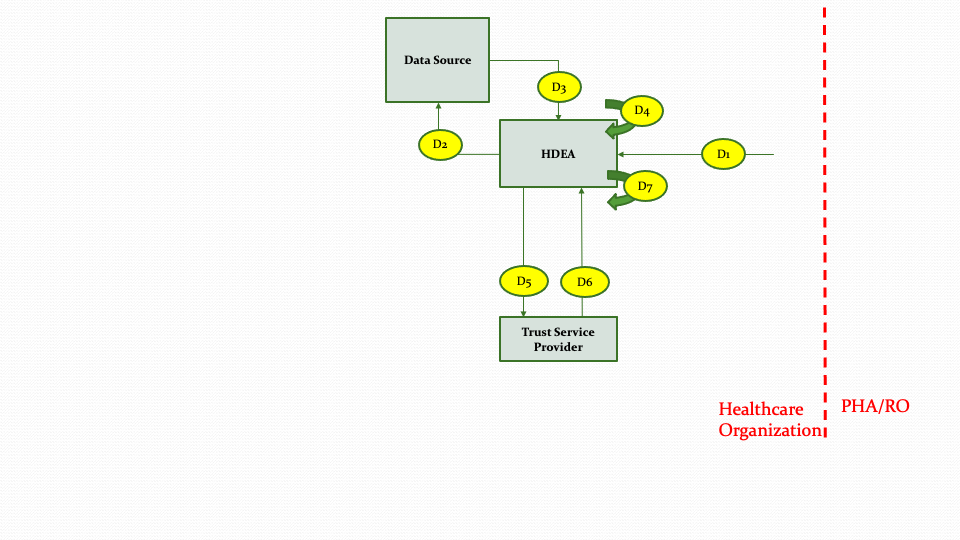
The descriptions for each step in the above diagram are described below:
Step D1: The data collection and submission report creation workflow is triggered for a specific patient based on the output of the Notification Workflow.
Step D2: The HDEA queries the Data Source to retrieve the necessary data for the patient to create the submission report.
Step D3: The Data Source returns the data for the queries from step D2.
Step D4: The HDEA processes the data returned from the Data Source, applying necessary filters and logic as appropriate.
Step D5: The HDEA based on the type of submission will invoke the Trust Servce Provider to de-identify or pseudonymize, hash or anonymize the collected data before generating the report.
Step D6: The Trust Service Provider returns after de-identifying or pseudonymizing, hashing or anonymizing the data based on the request in Step D5.
Step D7: The HDEA creates the submission report from the data collected for submission.
NOTE: Steps D5 and D6 only occur if the information in the Knowledge Artifact (based on use case need) requires de-identifying, pseudonymizing, hashing, or anonymizing.
The Data Submission Workflow involves the activities whereby the HDEA packages and submits the data to the Data Receiver (e.g., PHA or RO). The data submission may occur through a TTP. The actors and steps involved in the workflow are shown in Figure 3.4 below.
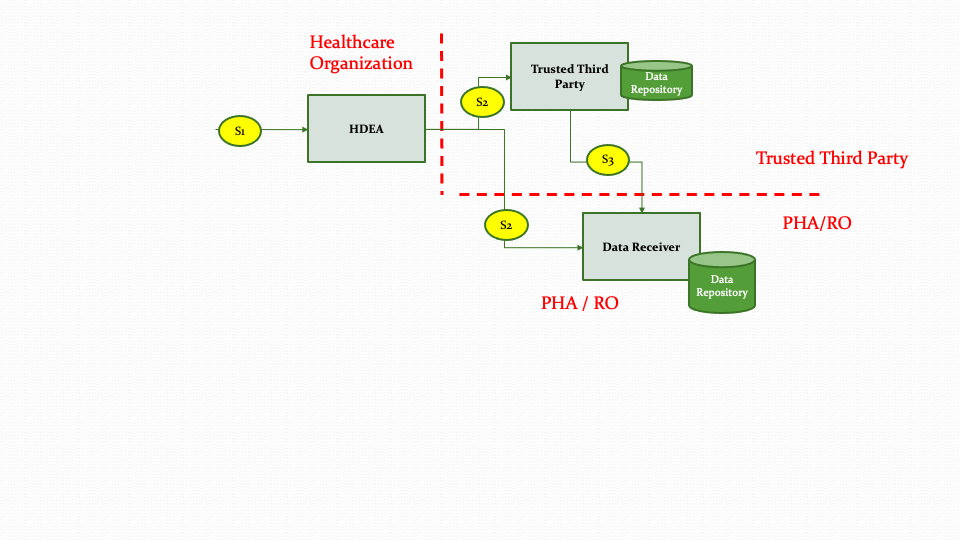
The descriptions for each step in the above diagram are described below:
Step S1: The data submission workflow starts after the report is generated by the Report Creation workflow and the report is validated.
Step S2: The HDEA uses the FHIR APIs to submit the report to the Trusted Third Party or to the Data Receiver directly based on authorities and policies.
Step S3: When data is received by the Trusted Third Party, it forwards the data to the Data Receiver based on applicable requirements, authorities and policies.
The Receiving Response/Acknowledgement Workflow involves the activities whereby the Data Receiver provides a response back to the Healthcare Organization. This workflow depicts the PUSH method (i.e., PUSH from Data Receiver to Healthcare Organization). The actors and steps involved in the workflow are shown in Figure 3.5 below.
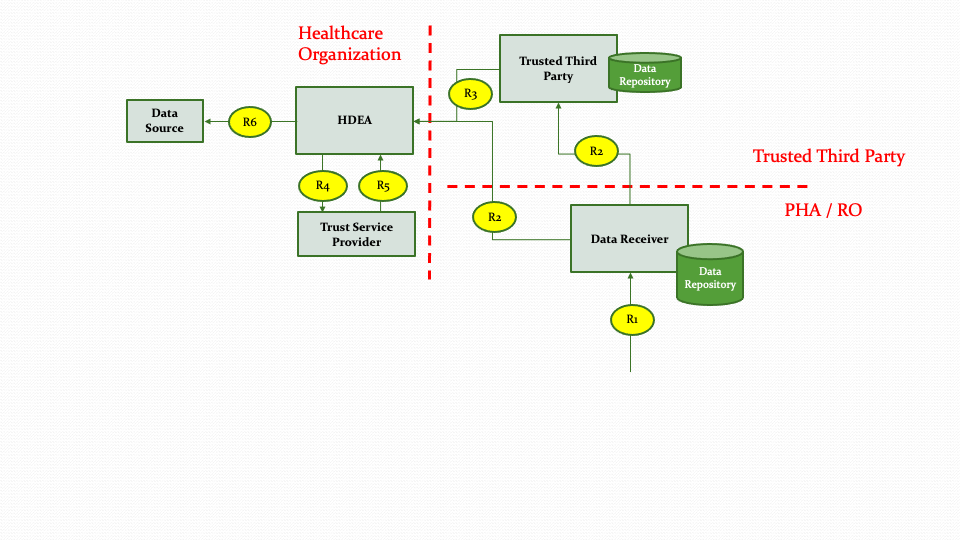
The descriptions for each step in the above diagram are described below:
Step R1: The Data Receiver analyzes the data received from the Data Submission workflow and crafts a response to be sent back to submitting Healthcare Organization.
Step R2: The Data Receiver then submits the response or acknowledgement to the Healthcare Organization directly or via Trusted Third Party based on authorities and policies.
Step R3: The Trusted Third Party routes the response or acknowledgement received from the Data Receiver to the Healthcare Organization.
Step R4, R5: The HDEA receives the response or acknowledgement and re-identifies the data as needed.
Step R6: The HDEA forwards the response or acknowledgement back to the Data Source.
Figure 3.7 below shows the research abstract model to on-board a data partner who can contribute data from their Data Source system to populate a Data Mart.
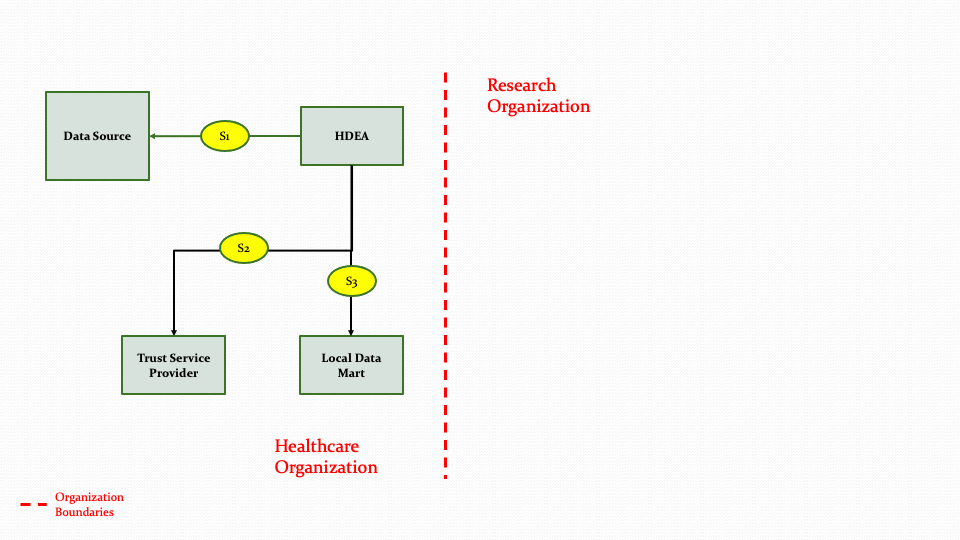
The descriptions for each step in the above diagram are described below:
Step S1: The HDEA initiates an extraction process to get data from a Data Source for one or more patients.
Step S2: The HDEA then uses the Trust Service provider to de-identify, anonymize, hash, or pseudonymize the data.
Step S3: Once the data is transformed in step S2, the data will then be populated into the Data Mart. The transformation process is not part of the MedMorph scope.
As shown in Figure 3.6 above, the HDEA will extract data from a Data Source for one or more patients and use the Trust Service Provider to perform de-identifying, anonymizing etc. as needed and then populate the Data Mart. In Figure 3.6, the Data Mart exists within the Healthcare Organization. The Data Mart and the HDEA could reside outside the Healthcare Organization as shown in Figure 3.7 below.
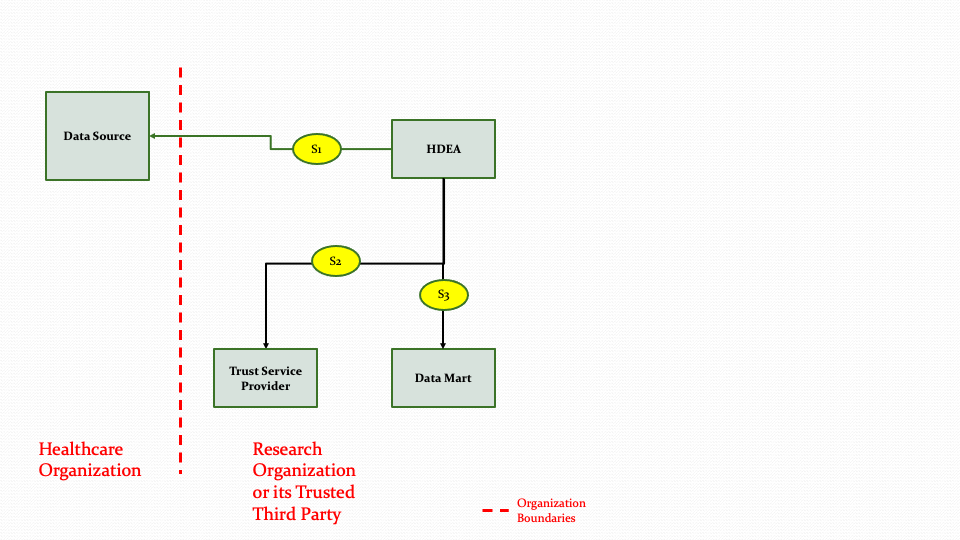
The descriptions for each step in the above diagram are described below:
Step S1: The HDEA initiates an extraction process to get data from a Data Source for one or more patients.
Step S2: The HDEA uses the Trust Service provider to de-identify, anonymize, hash, or pseudonymize the data.
Step S3: Once the data is transformed in Step S2, the data will then be populated into the Data Mart. The transformation process is not part of the MedMorph scope.
IG © 2020+ HL7 International - Public Health Work Group. Package hl7.fhir.us.medmorph#1.0.0 based on FHIR 4.0.1. Generated 2023-06-08
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change