
International Birth And Child Model Implementation Guide
1.0.0 - STU 1
![]()
International Birth And Child Model Implementation Guide
1.0.0 - STU 1
![]()
International Birth And Child Model Implementation Guide, published by HL7 International / Patient Care. This guide is not an authorized publication; it is the continuous build for version 1.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/fetal_records/ and changes regularly. See the Directory of published versions
| Page standards status: Informative |
No one disputes that when a infant is born, the newborn infant can be a patient with its own unique identifier. The mother herself is also a recognizable patient, but prior to this IG there are no consistent rules for addressing information directly pertinent to fetus prior to birth. Some systems record the data of the fetus as a body tissue of the mother. Other systems do have some form of resource that resembles a patient. There exists a need to relate the data, such as specific observations (e.g. femur length) or conditions, to the fetus, because such data are characteristics of the fetus and not the mother. In cases of multiples (e.g. twins or triplets) features of each fetus may need to be distinguished from each other.
Our goal is to provide guidelines about the communication of data around the fetus. As project team from HL7 PCWG we are aware that we cannot enforce how data is structured within an EHR system, but we can set up rules on how data should be communicated between systems. A similar way of handling these data would make the ease of connecting systems to each other and comparison of data much easier.
All countries collect data of pregnancy and birth for their vital health statistics and research purposes. The fact that we set rules how to use certain FHIR resources could make it more complex. You might need to search data of this specific resource. But this resource does not always exist. This document will also address these issues.
This Implementation Guide will address the following questions:
The FHIR resource that will be used to represent a fetus is a simplified Patient resource. This is a Patient extension that is called: Patient with fetal status extension. This decision has been taken in collaboration with the Patient Administration Work group at the HL7 WGM of May 2024 in Dallas (TX). This artifact is explained in detail under the tab of Artifacts.
At first this resource was called the Patient with born status extension, but the subject is not meant to be related to the event of birth. This also collided with concepts and explanation of terms that were used by Public Health in vital statistics, where they preferred to use the term delivery, instead of birth. The CHOICE group has therefore renamed the FHIR extension to reflect that the subject of related data is a fetus. It is all about the subject fetus and has nothing to do with delivery.
Detailed information about the pros and cons of the different options can be found in first release of the IG of IBCM.
Having chosen for an extension of the FHIR resource Patient does have implications for systems that are active in this sector. This implies that all systems that communicate data about the fetus must support this extension. If a system, for example an EHR, receives a reply where this FHIR extension is used and it does not understand this FHIR resource, then the communication will fail and end up in an error.
Implementers conforming to a particular profile in the IBCM Implementation Guide:
The sequence when we are introducing the implementation of this new FHIR resource in a certain region, is that all receiving systems should be ready for processing the FHIR extension first, before systems that are transmitting will start using the new FHIR extension. There will be a transition period where receiving systems need to be able to interpret an old method and the new way of communicating with the new FHIR extension.
At the start of pregnancy when findings are observed and collected the first form of new life starts as an embryo. In general the findings are either classified as characteristics of the mother as the patient, or are findings attached to the episode of pregnancy. As the pregnancy lingers on, the embryo will develop its own characteristics. The question arises when do we consider relating data to a separate resource (instead of the mother)? The guideline is to attach the characteristic data to the proper subject. In the episode of pregnancy the main subjects to which data could be related to are either:
Obvious examples of characteristics of the fetus are measurements like femur length or heart beat of the fetus. Obvious examples of data attached to the pregnancy are the parity and gravidity of the pregnancy. This means that once data is classified as characteristics of the fetus, it should be communicated as data attached to the fetus as a resource.
This could mean in certain cases that in some pregnancies data was never communicated with findings attached to a fetus, because it was never observed and registered. This is for example the case of an early demise. This could lead to issues when performing research. For the time being this is left out of scope of the current project.
When communicating data with the Patient with fetus status extension, the FHIR resource has the possibility to contain an identifier. This identifier is not mandatory and in most cases this will not create any issues, because the pregnancy involves only one fetus and is usually accompanied with data about the mother with her identifier.
However some organizations do prefer to use a unique identifier for the fetus to make the subject identifiable throughout the process and the history. Certainly in the case of multiple fetuses it is necessary to be able to distinguish which data belongs to which fetus. Therefore it could be sensible to always use an identifier when communicating the data with the FHIR resource.
There are some notes to be made about appointing an identifier. This is also dependent on the way the data is stored in the medical records. As mentioned earlier 2 methods are generally used either, as a body tissue or as a pseudo patient
 |
We recommend using a persistent identifier to track data throughout the pregnancy episode, potentially extending after birth. It's common for the mother and fetus to receive care in different institutions, such as starting at a midwife's office, moving to a hospital, and involving other facilities like ultrasound labs or neonatal hospitals. Each system may have its own identifier generation and acceptance process.
The identifier should be generated at the start, when the first system recognizes the fetus. If the system links the subject to body tissue, that identifier is passed as the patient identifier with a fetal status extension in FHIR. If a pseudo patient is used, a patient identifier is generated.
All subsequent systems handling fetal data must retain and transfer the same identifier.
Challenges arise in systems that expect a fixed format (e.g., a national patient identifier). They must accommodate a different format for the fetus, and in cases of multiple fetuses, each must have a unique identifier. Typically, identity is linked to the fetus's position in the womb, though this may change over time and require visual confirmation.
There are several methods for generating an identifier:
As mentioned in paragraph A the data should preferably be a characteristic of the proper subject. We know that many systems do not follow this rule every time. For example the (biological) father of the fetus is often not recognized as a separate entity, but that is not the scope in this project. In this implementation guide the guideline is, that data should be related to the proper entities:
The relationship between fetus and mother can be expressed in FHIR using the RelatedPerson resource. The type of relationship is expressed in the attribute relationshiptype. Usually, the relationship type would be ‘MTH’ but more specific codes are available to address concepts like biological mother, donor mother and gestational mother. Note that a fetus will have both a RelatedPerson instance for the donor mother and a RelatedPerson instance for the gestational mother in case of egg cell donation.
The use of a simplified FHIR patient resource extension has the advantage that many FHIR resources, such as procedures or observation are accustomed to have a patient as a subject. No special adjustments are required for other FHIR resources to be able to place the fetus as subject. This would not be the case if we had invented a new FHIR resource.
Most countries have methods of collecting data for birth and fetal death reporting. Countries do compare their vital statistics on a global level, but there is no universal guideline on how the data should be collected. This is mostly organized on the National level and healthcare institutions and care providers in a certain country are bound to these National agreements.
The Implementation Guide for the USA for birth and fetal death reporting using FHIR can be found here. Other countries might have their own implementation guides on birth and mortality reporting.
These Implementation Guidelines for these vital statistics will be compelling for these countries. Therefore the CHOICE project does not produce specifications that might overlap in this information space and cause confusion with the birth or fetal death reporting. CHOICE does not dictate how data is stored and therefore birth and fetal death reporting should be reported as it has to be done on a National level.
When we look at the data in the pregnancy period we can distinguish the following data categories:
The scope of this Implementation Guide is the fetus data, although for completeness the examples may also contain maternal and child-specific maternal data. Child data is out of scope of this Implementation Guide since in this case the child is born and the data will become attached to a regular FHIR Patient representing the child. After birth the fetalStatus extension will no longer be used.
Although we do not express any mandatory rules about the storage of the fetus data itself, we did have several conversations about the possibilities and difficulties about this topic.
There are 2 options that we would like to illustrate:
The figure below illustrates the situation where the fetus refers to data residing with the mother:
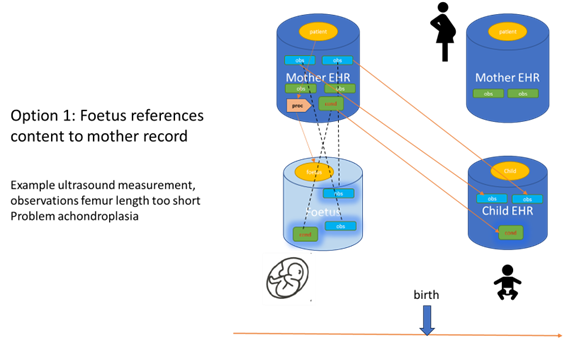 |
This illustration suggests that the actual data of the diagnostics are attached to the mother as a patient. So the source of the data remains with the mother patient. The fetus, whether it is a pseudo patient or a body tissue, is only referencing the data of the mother. When the child is born a real patient record is created for the child and data related to the fetus is copied across to the new child record as well as data from the mother and pregnancy period. In case of demise before birth no child record will be created. The pseudo patient ceases to exist, but the findings will still be available at the mother record.. Our view is that it is better to focus on reuse of data rather than copying and transforming data between a mother record and a patient record. Instead a (restricted) view from the child record on the mother record could be possible, which allows access to all data from the mother record that is medically relevant for the child (as well as the other way around). Of course, this might still be a big challenge in real practice and legal frameworks should be taken into account (especially in special circumstances where the child grows up in foster care for example). But these questions should be addressed by implementers of these kinds of systems.
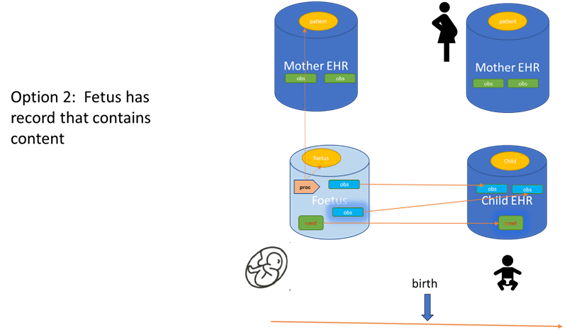
The figure below shows the situation, where the fetus contains it’s own data:
 |
IG © 2023+ HL7 International / Patient Care. Package hl7.fhir.uv.ibcm#1.0.0 based on FHIR 5.0.0. Generated 2025-08-29
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change