HRSA 2024 Uniform Data System (UDS) Patient Level Submission (PLS) (UDS+) FHIR IG
2.0.0 - STU2 Release 1 - Standard for Trial-Use
![]()
HRSA 2024 Uniform Data System (UDS) Patient Level Submission (PLS) (UDS+) FHIR IG
2.0.0 - STU2 Release 1 - Standard for Trial-Use
![]()
HRSA 2024 Uniform Data System (UDS) Patient Level Submission (PLS) (UDS+) FHIR IG, published by HRSA BPHC. This guide is not an authorized publication; it is the continuous build for version 2.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/drajer-health/uds-plus/ and changes regularly. See the Directory of published versions
| Page standards status: Trial-use |
The section identifies the business needs and specific user stories for UDS+ reporting.
Each calendar year, HRSA Health Center Program awardees and look-alikes are required to report a core set of information, including data on patient characteristics, services provided, clinical processes and health outcomes, patients' use of services, staffing, costs, and revenues as part of a standardized reporting system known as the Uniform Data System (UDS). The UDS is a standard data set that is reported annually and provides consistent information about health centers. It is the source of unduplicated data for the entire scope of services included in the grant or designation for the calendar year. HRSA uses UDS data to assess the impact and performance of the Health Center Program, and to promote data-driven quality improvement.
The goals of the use case is to transmit de-identified patient information to HRSA as part of the annual health center submission. The intent is to provide access to data not currently available through aggregate data reporting. The use case will help assess how to address the gaps in workflow and triggers, and the ability to leverage HL7 FHIR APIs to address HRSA business needs.
Presently health centers submit UDS data using a tabular format. The submitted data is aggregated at sites and submitted to HRSA using different mechanisms such as uploading files to a portal, submitting via SFTP.The Bureau of Primary Health Care (BPHC) will transition much of the UDS from aggregate data to de-identifeid patient-level data by 2023. The
The following are some of the challenges which need to be addressed:
The goal of the use case is to
In-Scope
The following requirements are in-scope for the IG.
Collect data from health centers that receive federal award funds (“awardees”) under the Health Center Program authorized by section 330 of the Public Health Service (PHS) Act (42 U.S.C. 254b) (“section 330”), as amended (including sections 330(e), (g), (h), and (i))
Collect data from health centers considered Health Center Program look-alikes. Look-alikes DO NOT receive regular federal funding under section 330 of the PHS Act (although they may receive funding during public health emergencies, such as COVID-19), but meet the Health Center Program requirements for designation under the program (42 U.S.C. 1395x(aa)(4)(A)(ii) and 42 U.S.C. 1396d(l)(2)(B)(ii)).
Collect data from health centers funded under the Health Resources and Services Administration’s (HRSA) Bureau of Health Workforce (BHW)
Define the requirements for a health center to create and transmit a UDS+ report to HRSA
Identify the data elements to be retrieved from the Data Sources (e.g., EHRs, Data Warehouses etc) to produce reports
Out-of-Scope
At the end of the calendar year, a health center which is a HRSA awardee, has to submit the UDS+ report. The health center uses an EHR as the Data Source for all its data capture, storage and reporting. The Data Source is a certified EHR system and supports the FHIR APIs outlined in Cures Act including Bulk API for exporting data for a population.In order to perform the reporting, the health center identifies the list of all the patients who have availed services that need to be reported to HRSA and creates a Group using the certified FHIR APIs. (Note: For some health centers, it may be all the patients and for others it could be sub-set of the patients). Once the population is identified, the health center extracts the UDS+ data for the patients from the Data Sources (e.g., EHRs) and then de-identifies the data and prepares the data to be submitted in a standard FHIR format. The health center then notifies HRSA about the data readiness and submits the data to HRSA using FHIR APIs.
The following is a diagram of the workflow for UDS+ reporting using FHIR APIs
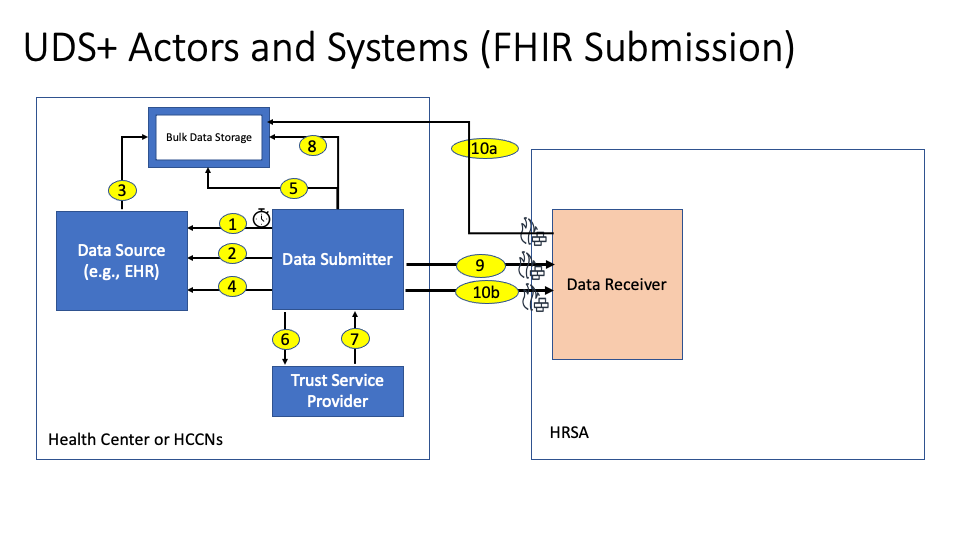
The description of each step in the above interaction is outlined below:
Implementation Note This step is expected to be kicked off by the Health Center or the EHR vendor using a scheduled job or a cron job or a timer. This job will initiate a Bulk Data Export request from the EHR for the UDS Plus Group.
Implementation Note This step is performed using the Bulk Data Status Request.
Implementation Note This step is implemented by the EHR based on their internal implementation on how and where to store the data for download. Once the data is stored the links are submitted to the Data Submitter for download.
Implementation Note This step is performed using the Bulk Data Status Request.
Implementation Note This step is happening within the environment (behind the firewall) of the Health Center and the data is downloaded using the Bulk Data File Request
Implementation Note This step is performed by the Data Submitter by invoking the de-identify operation of the Trust Service Provider
Step 7: The Trust Service Provider submits the de-identified data back to the Data Submitter.
Step 8: The Data Submitter persists the data for HRSA in a Bulk Data Storage and creates links for HRSA to download the data.
Implementation Note This data may be persisted outside of the EHR environment or within the EHR environment depending on the EHR.
Implementation Note The Data Submitter creates the Manifest file and then notifies the HRSA system of the availability of the files using the $import operation. The Data Receiver creates a Content Location where the status of the upload is updated as the download progresses. The status fields will provide one of the following values "submitted, inprogress, completed, failed".
Implementation Note The Data Receiver downloads the bulk files using the appropriate protocols and authorization. Currently this is done with HTTP protocols and using secured signed links.
Implementation Note The Data Receiver provides an update on the status of the submission and may include a list of errors and warnings for the submission. If the submission status is failed, the Data Submitter has to re-submit the data after addressing the errors provided by the Data Receiver.
The proposed solution above leverages already existing standards implemented by CEHRT systems namely the Bulk API Group Export and the US Core profiles. However implementations may choose to use other methods to export data and de-identify the data. Health Centers and their technology vendors may choose any other method to export the necessary data from the data source and may use any algorithm to de-identify the data. Usage of the above workflow enables more standardization over time within the health center and less dependence of proprietary solutions for creating the UDS+ report.
Health Centers from time to time may submit a UDS+ report that is erroneous in terms of
In some or all of the above cases, the Data Receiver will submit a list of errors in the submission. These errors need to be addressed by the Health Center and then resubmit the UDS+ report. Within the allowed reporting timeframe, a health center may resubmit the report multiple times. The resubmission should be a full data set resubmission. All submissions prior to the latest submission will be discarded and will not be considered for Health Center UDS+ reporting.
The following actors and definitions are used by the UDS+ use cases.
Data Sources The Data Source is a software system that is used to capture and store the patients electronic medical record which contains information such as patient demographics, medications, procedures, allergies, diagnosis, problems etc. Examples of Data Sources include EHRs, Data Warehouses etc. The Data Source is responsible for providing interfaces to extract patient data.
Data Receiver The Data Receiver is the HRSA organization. The data receiver is responsible for receiving the health center data, validate it and transform it for consumption by HRSA systems.
Data Submitter The Data Submitter system is responsible for extracting the data for the patients whose data need to be submitted to HRSA, de-identify the data and then notify about the readiness of the data to the Data Receiver.
Trust Service Provider The Trust Service Provider actor provides an API for de-identifying the patient data and creating the necessary linkages across the resources.
This section identifies how a health center may deploy the various UDS+ actors and systems and combine or split them for efficiency.
In this scenario a Data Source (e.g., Certified EHR) may implement the required functionality to support UDS+ reporting completely and may not require any additional systems. This deployment option is shown in the figure below
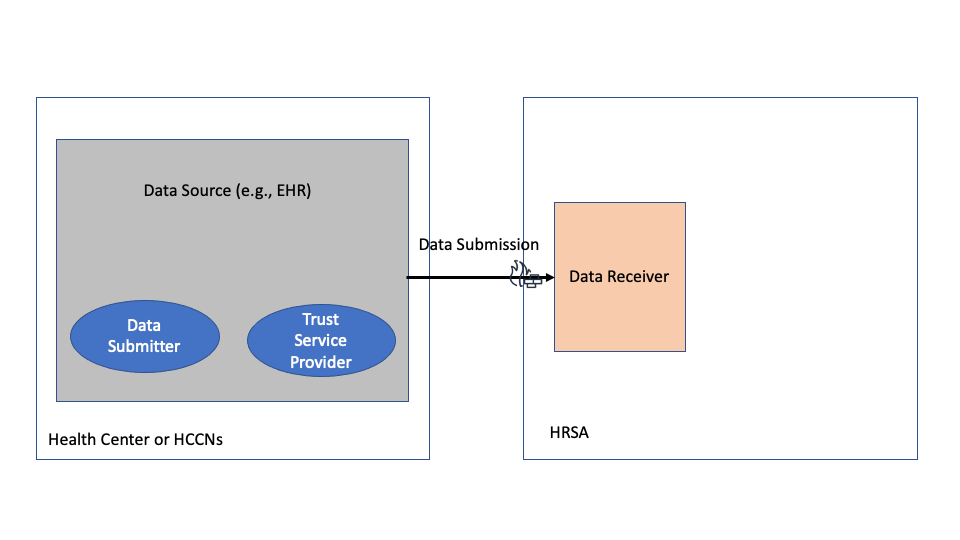
Health Centers are advised to coordinate with their Data Source (e.g., EHR) vendors to understand their existing capabilities and determine if this option is available.
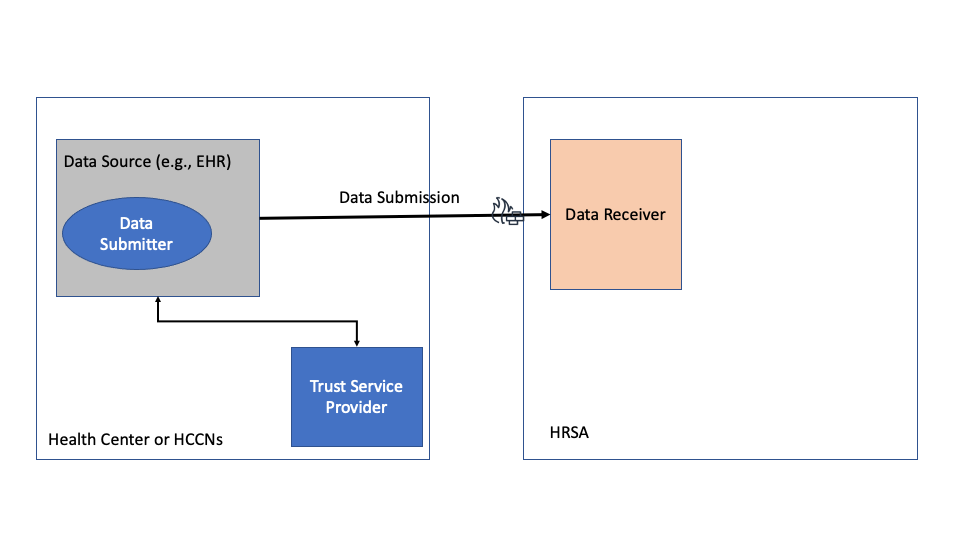
In this scenario a Data Source (e.g., Certified EHR) may implement the required functionality to support UDS+ reporting by extracting the necessary data in a de-identified form. In this deployment, the Health Center has to use a different system to act as the Data Submitter which receives the de-identified data extracts and then submits the data to HRSA. This deployment option is shown in the figure below
Health Centers are advised to coordinate with their Data Source (e.g., EHR) vendors to understand their existing capabilities and determine if this option is available.
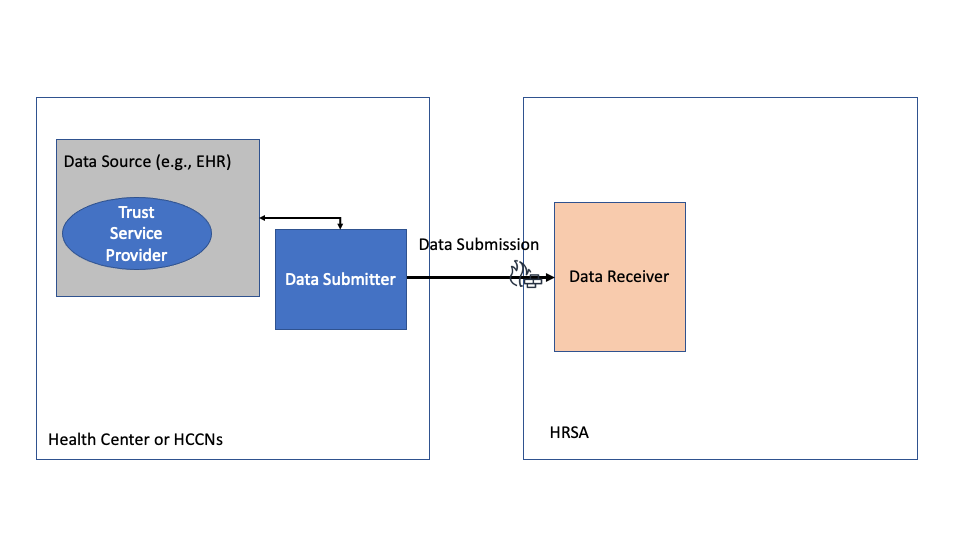
In this scenario a Data Source (e.g., Certified EHR) may implement the required functionality to support UDS+ reporting by extracting the necessary data and is capable of submitting the data to HRSA. However the Data Source may not be able to de-identify the data and may require an external service to de-identify the data. In this deployment, the Health Center has to use a different system to de-identify the data and then provide the data back to the Data Source/Data Submitter. This deployment option is shown in the figure below
Health Centers are advised to coordinate with their Data Source (e.g., EHR) vendors to understand their existing capabilities and determine if this option is available.