

Mobile Cross-Enterprise Document Data Element Extraction (mXDE)
1.3.1-current - ci-build
![]()
Mobile Cross-Enterprise Document Data Element Extraction (mXDE)
1.3.1-current - ci-build
![]()
Mobile Cross-Enterprise Document Data Element Extraction (mXDE), published by IHE IT Infrastructure Technical Committee. This guide is not an authorized publication; it is the continuous build for version 1.3.1-current built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/IHE/ITI.mXDE/ and changes regularly. See the Directory of published versions
The Mobile Cross-Enterprise Document Data Element Extraction (mXDE) Profile provides the means to access data elements extracted from shared structured documents. The profile enables the deployment of health data exchange infrastructures where fine-grained access to health data coexists and complements the sharing of coarse-grained documents and the fine-grained data elements they contain.
A challenge that Document Sharing has is on the consuming side. The Principles of a Document are more beneficial to the source. The source is in control of each document creation, and content. Therefore, a consuming application must be robust to the fact that the data may not be broken down or organized in a way that is helpful to the consumer application. There may not even be the information that the consumer wants in any given document.
This profile is based on the reality that health information sharing relies on different granularities of exchange:
This profile defines rules to ensure consistency and traceability of information used for clinical decisions. When a data element is accessed by a Clinical Data Consumer, identifiers from that data element can be used to access one or more documents in which this data element was originally recorded, providing a valuable broader clinical context.
The flows of information are depicted in the Figure 1:45-1:
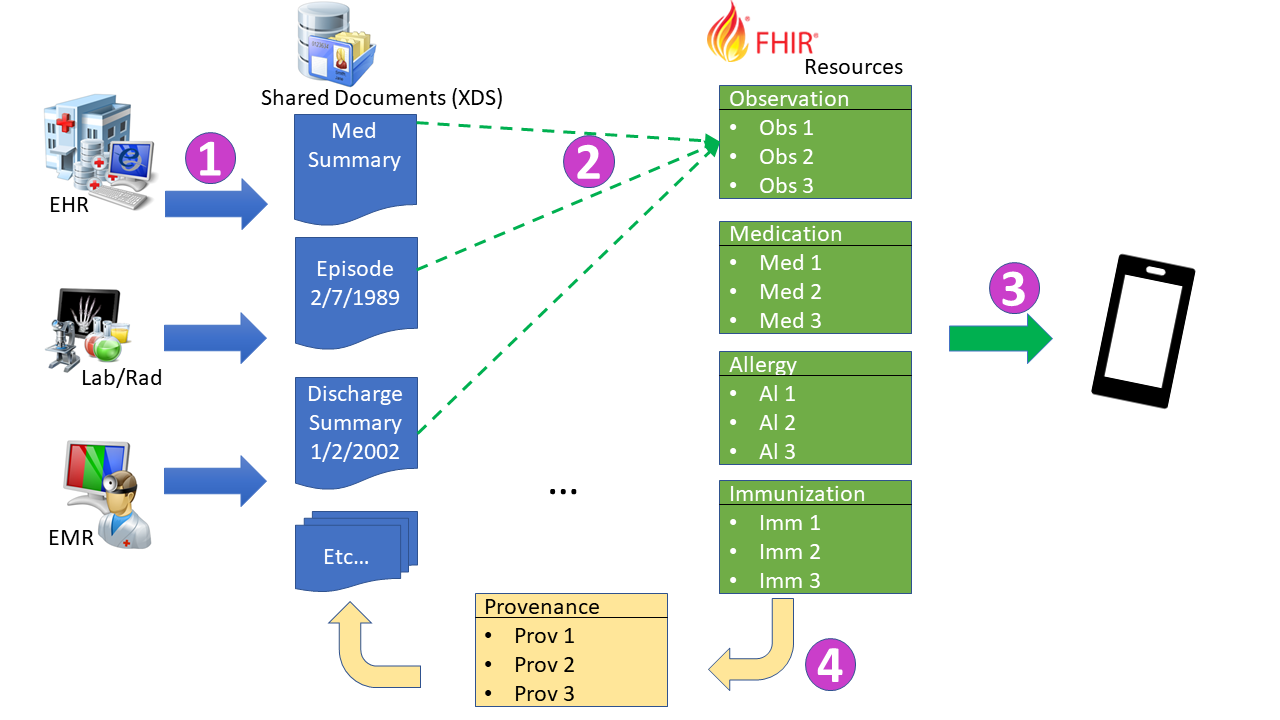
This is all described more fully in the HIE Whitepaper.
This profile defines rules to ensure consistency and traceability of information used for clinical decisions. When a data element is accessed by a Clinical Data Consumer, identifiers from that data element can be used to access one or more documents in which this data element was originally recorded, providing a valuable broader clinical context.
The mapping of the document to data elements is outside the scope of the mXDE Profile. It needs to be specified for each deployment based on the specific document content and data elements managed.
This profile supports a variety of deployment models discussed in Section 1:45.7.
This section defines the Actors, Transactions, and Content Modules in this implementation guide. Further information about actor and transaction definitions can be found in the IHE Technical Frameworks General Introduction Appendix A: Actors and Appendix B: Transactions.
The mXDE Profile includes two actors:
Table 1:45.1-1 lists the transactions for each actor directly involved in the mXDE Profile.
Table 1:45.1-1: mXDE Profile - Actors and Transactions
| Actors List | Transactions | Optionality | Reference |
|---|---|---|---|
| Data Element Extractor | None | - | - |
| Clinical Data Consumer | None | - | - |
This section documents any non-transaction specific actor requirements.
Defined in Data Element Extractor requirements CapabilityStatement:
Definition in Clinical Data Consumer requirements CapabilityStatement:
Options that may be selected for each actor in this implementation guide, if any, are listed in Table 1:45.2-1 below. Dependencies between options when applicable are specified in notes.
Table 1:45.2-1: mXDE - Actors and Options
| Actor | Option Name | Reference |
|---|---|---|
| Data Element Extractor | None | - |
| Clinical Data Consumer | None | - |
An actor from this profile (Column 1) shall implement all required transactions for the grouped actor (Column 3) in the Required Actor Groupings Table as shown below.
Note that each one of the three alternatives of actor diagrams specified for the mXDE Implementation Guide in Section 1:45.1 has different required actor groupings.
Table 1:45.3-1: mXDE Profile - Required Actor Groupings
| mXDE Actor | Grouping Condition | Actor(s) to be grouped with | Reference |
|---|---|---|---|
| Data Element Extractor | Required | PCC QEDm / Clinical Data Source with the Document Provenance Option | PCC QEDm |
| Optional | PCC Content Consumer | PCC TF-2:3.1 | |
| Required | ATNA / Secure Node or Secure Application | ITI TF-1: 9 | |
| Clinical Data Consumer | Required | PCC QEDm / Clinical Data Consumer with the Document Provenance Option | PCC QEDm |
| Required | PCC Content Consumer | PCC TF-2:3.1 | |
| Required | ATNA / Secure Node or Secure Application | ITI TF-1: 9 |
PCC Content Consumer is an abstract actor that can be implemented by the various Document Sharing exchanges. The actual capabilities would be indicated in the products IHE Integration Statement with grouped specific Document Sharing Profile and Actor statements.
Section 1:45.5 Security Considerations describes some optional groupings that may be of interest for security considerations and Section 1:45.6 Cross Profile Considerations describes some optional groupings in other related profiles.
Section 1:45.7 Deployment Models describes some groupings based on some defined deployment models
See “Profile Introduction and Concepts” in Section 1:45.
The use case below assumes that every consumer device (mobile or not) knows or discovers the patient identity. The patient identity could be obtained through a transaction in an IHE Profile such as PDQ, PDQm, PIX, or PIXm, or it could simply be entered via some device interface (RFID, Bar-Code, etc.) or user interface, or it could be specified in a configuration setting (e.g., mobile PHR application).
A human using a consumer device needs to discover the available information of a certain patient and to retrieve the parts of interest in order to get coarse and fine-grained data based on the patient identity and on certain search criteria.
A patient encounters his family physician who advises him to make an appointment for a surgical procedure. Consequently, the family physician produces and shares a Transfer of Care document in an XDS Affinity Domain. He also shares a Pharmacy Prescription document.
Following the encounter, the patient makes an appointment with the local hospital for the intended surgery. He also picks up his prescribed medication at the local pharmacy which results in the pharmacy sharing a Pharmacy Dispensation document.
In particular, this use-case assumes that a consumer application running on a mobile device (e.g., the patient’s smartphone and the family physician’s tablet) supports IHE actors designed for mobile use including, but not limited to, the MHD Document Consumer and the QEDm Clinical Data Consumer Actors. However, different actor groupings could be conceived. The only required groupings in the mXDE Profile are those specified in Section 1:45.3.
The combination of Document Sharing, Query for Existing Data, and Document Element Extraction support these use-cases combined. Logically there are the Grouped Client systems that have grouped QEDm Clinical Data Consumer, mXDE Clinical Data Consumer, and some Content Consumer (e.g. XDS Document Consumer, MHD Document Consumer, etc); and a Grouped Server system that have grouped QEDm Clinical Data Source, mXDE Data Element Extractor, and some for of Document Sharing infrastructure (e.g. XDS, XCA, MHD, etc). The transactions between these two grouped systems is using transactions defined else where within Document Sharing.
The Grouped Server will respond to the externally visible transactions as defined. The Grouped Server needs to do background processing to fulfill the mXDE Data Element Extractor responsibility. This processing is depicted in the following diagram
.target) at each clinical Resource created or updated, and expresses when this extraction took place, and indicate what document these were extracted fromThe Grouped Client initiates the interaction based on some undefined need. There are many examples in the use-case above, including examples of why Provenance and Document content may be needed. Without the need for Provenance or the Document then the flow would simply be normal QEDm processing and not involve mXDE. For the use-case given there is identified need.
See ITI TF-2x: Appendix Z.8 “Mobile Security Considerations”
mXDE is a profile that supports the deployment of a system of systems, thus the security considerations should take into account the overall system design and also the interactions between actors that make up that system. The Security Considerations sections in the underlying QEDm, MHD, XDS Profiles, should also be taken into account in the system design and operational deployment.
IHE security profiles (e.g., ATNA, XUA, IUA, BPPC, APPC) provide functionality to aid with security and privacy. However, the interactions between various environments such as IUA and XUA can be challenging. XUA is used in the XDS environment and is based on SAML. IUA is used in QEDm and MHD environments and is based on OAuth technology. Bridging between these technologies is possible, but is not specified by this profile because bridging depends on specific deployment context.
The mXDE Data Element Extractor will often need to have an XUA identity by which it accesses documents for extraction. This identity would have broad read-only access to documents so that it can extract information. Yet when a Clinical Data Consumer queries for data-elements or documents, it will identify a user (e.g., clinician, patient, or organization). The queries would need to be mediated by access control decisions and enforcement that are appropriate. For example, when there is a document-level consent (e.g., BPPC, APPC, or other) and there is a consent restriction that is specified to denying a designated user access, then when that designated user attempts to access data-elements, the access needs to be denied. The solution is a policy and design challenge not addressed by this profile because it depends on specific deployment context.
The provenance solution included in mXDE and QEDm can be used by an access control decision engine. Given any data-element that might be returned on a query, the associated Provenance Resource includes traceability to the Document from which that data-element came. Thus, an access control decision that needs to filter out specific documents can use the Provenance information to determine the results that must be eliminated from the Bundle before the Bundle can be returned to the Data Element Provenance Consumer. The specific use of Provenance in access control decisions, and enforcement is a policy and design challenge not addressed by the QEDm Profile.
The Data Element Extractor, and actors with which it is grouped, is grouped with an ATNA Secure Node or Secure Application to provide logging and other security features (see ITI TF-2: 3.20). It is recommended that the Clinical Data Consumer be grouped with an ATNA Secure Node or Secure Application.
The mXDE Profile provides a controlled approach to access the same health information either in a document-level (coarse grain) granularity or in a data element level granularity (fine-grain). In some situations, the relationship between these two levels could result in defects in information integrity and/or credibility in the information being accessed.
The implementer of this profile should consider the following specific issues:
mXDE is designed to limit the above issues. It offers the means to avoid these weaknesses of the data element granularity by allowing the user that retrieves a query list to easily request the document(s) that are sources of the data element(s) of interest.
mXDE is a component of a broader Document Sharing exchange. The Enabling Document Sharing Health Information Exchange using IHE Profiles Whitepaper explains the various Document Sharing models, Patient Identity Management, Common Provider Directory, and Security and Privacy. This paper also includes references to implementations and further reading.
For the implementation of the mXDE Grouped Server, a number of actors that generally are considered as part of a health information sharing infrastructure may be organized in various architectural structures. Deployment models are identified for information in this section. These are not exhaustive and other variants may be supported.
In each one of these deployment models, the “interoperability” defined by mXDE is the same. The Grouped Client would not need to be aware of the Grouped Server deployment model.
In this deployment model, all of the health information infrastructure is designed around a centralized system that groups a the mXDE Data Element Extractor with an XDS Document Registry, an XDS Document Repository and a QEDm Clinical Data Source to which the fine-grained queries are directed.
In this model the interactions between these Grouped Server actors do not need to be visible externally, and thus can be designed internally in any way. They do not need to use formally defined IHE transactions, but might.
The drawback of this model is that the mXDE Data Element Extractor is bound to the server infrastructure and can not be connected to actors provided elsewhere.
In this deployment model, the health information infrastructure is designed around a centralized system that groups a mXDE Data Element Extractor to an XDS Document Registry and a QEDm Clinical Data Source to which the fine-grained queries are directed, while the multiple Document Repositories are decentralized.
Because of the decentralized nature of the Document Repositories, the mXDE Data Element Extractor must retrieve the documents from the various XDS Document Repositories for extracting and assembling the data elements and the provenance information to be shared with the Clinical Data Consumer. In this deployment model, the Grouped Server would need to implement a Content Consumer and interact using XDS or MHD Document Consumer.
This deployment model is a little more complex than the previous one as the Document Repositories may be distributed, but this complexity is transparent to the Clinical Data Consumers and Document Consumers.
In this deployment model, the health information infrastructure is independent of the mXDE Data Element Extractor and a QEDm Clinical Data Source to which the fine-grained queries are directed.
The mXDE Data Element Extractor must query and retrieve the documents from external Document Registry and Document Repository. In this deployment model, the Grouped Server (as shown above) would not include Document Sharing Infrastructure. The mXDE Data Element Extractor would need to implement a Content Consumer and interact using XDS, XCA, or MHD Document Consumer Actor. With XDS the DSUB profile may be used to trigger the mXDE Data Element Extractor to process newly published documents as they get published. Otherwise the mXDE Data Element Extractor would trigger on QEDm requests or continuously poll.
This deployment model is more general and could thus be connected to any Document Sharing infrastructure, depending on that infrastructure support for the XDS vs MHD Document Consumer grouped with the mXDE Data Element Extractor.
This deployment model is a more complex than the previous ones, but this complexity is transparent to the Clinical Data Consumers and Document Consumers.
IG © 2023+ IHE IT Infrastructure Technical Committee. Package ihe.iti.mxde#1.3.1-current based on FHIR 4.0.1. Generated 2024-11-26
Links: Table of Contents |
QA Report
| New Issue | Issues
Version History |
![]() |
Propose a change
|
Propose a change