
Clinical Practice Guidelines
2.0.0 - STU2
![]()
Clinical Practice Guidelines
2.0.0 - STU2
![]()
Clinical Practice Guidelines, published by HL7 International / Clinical Decision Support. This guide is not an authorized publication; it is the continuous build for version 2.0.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/HL7/cqf-recommendations/ and changes regularly. See the Directory of published versions
Knowledge execution refers to the processes of binding computable knowledge formalisms to data for the purpose of generating new information and insights. Details of knowledge execution are beyond the scope of this document, but has implications largely addressed in the section on Methods of Implementation.
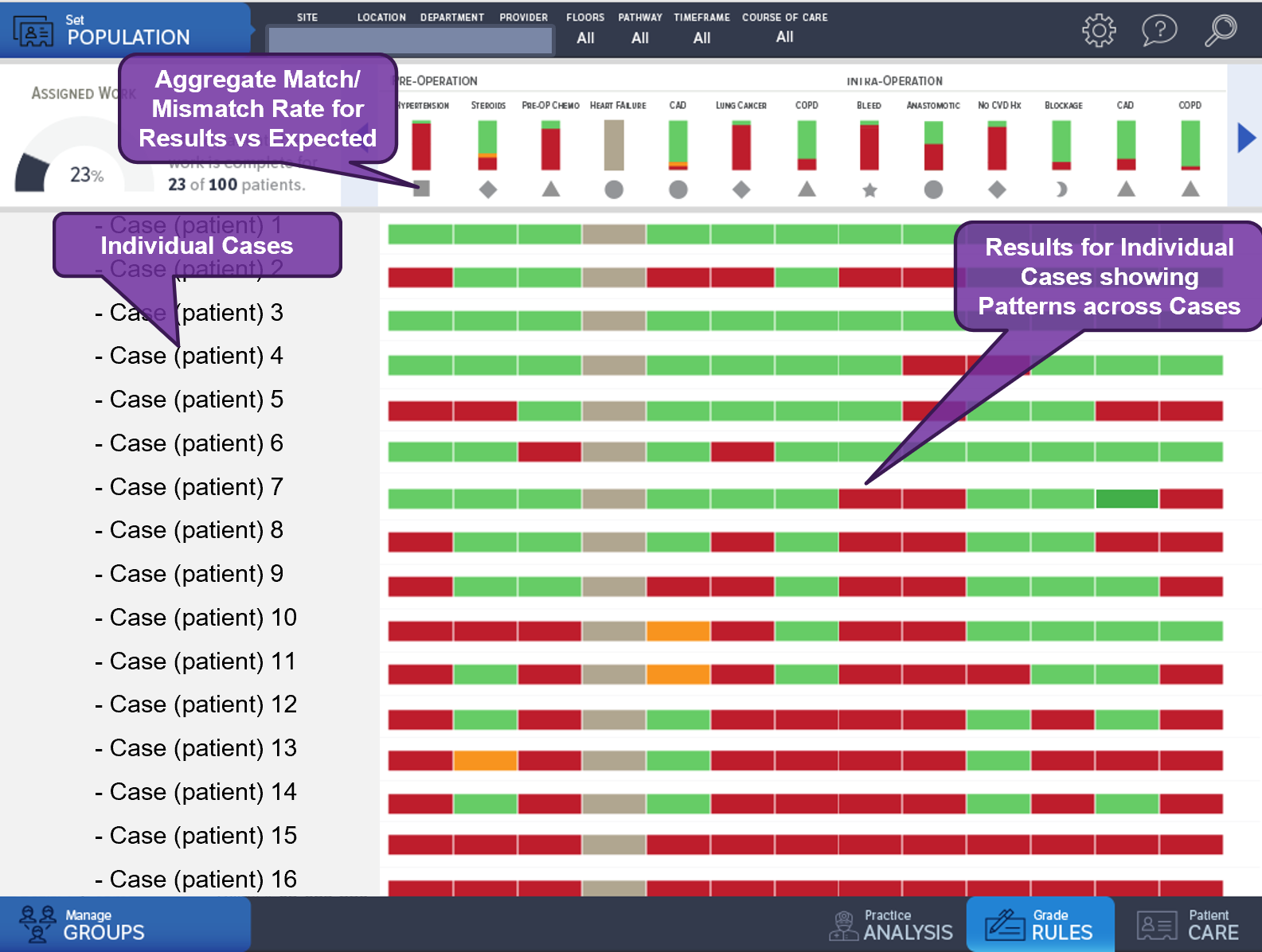
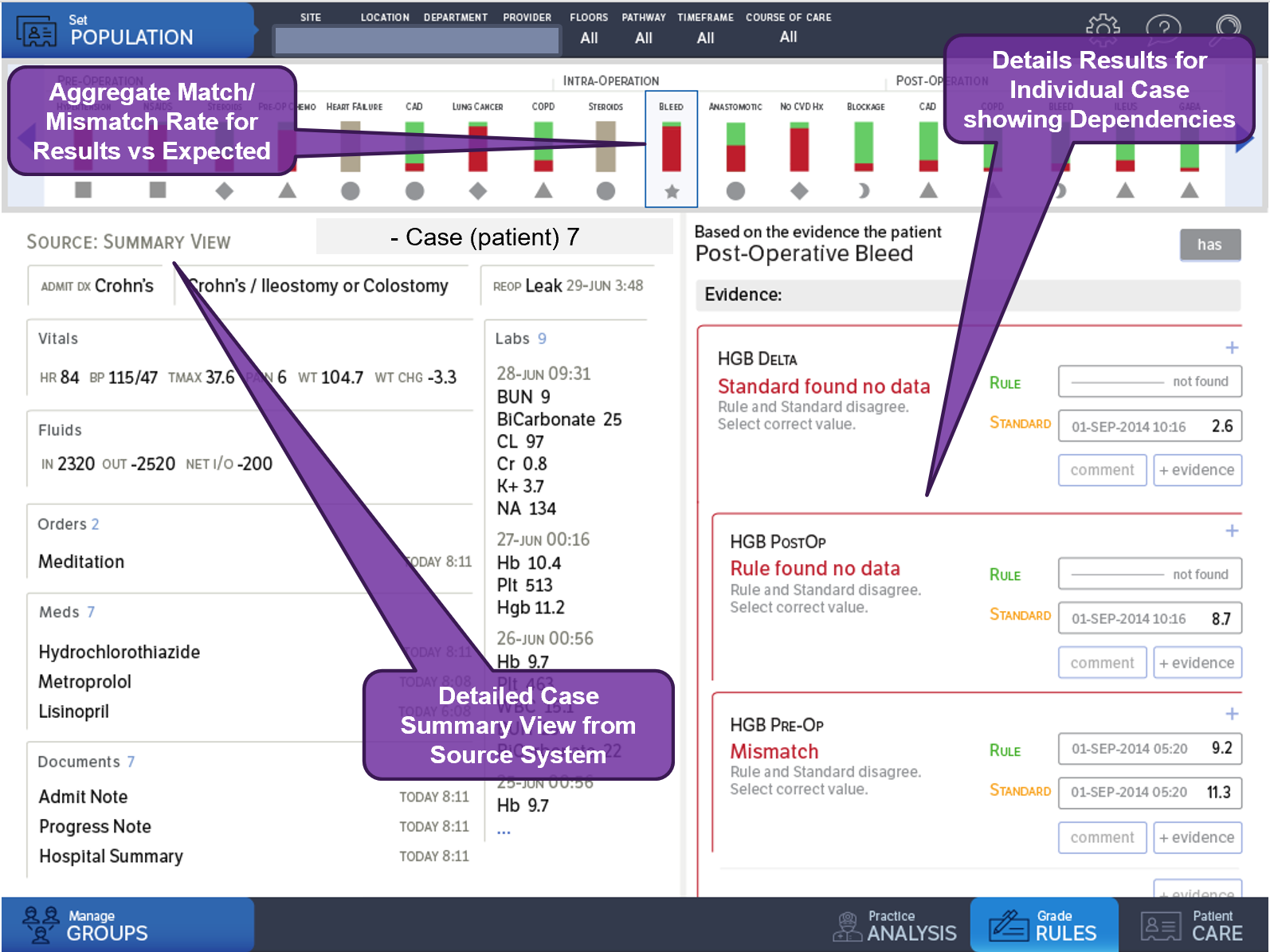
Knowledge validation refers to verifying that the various knowledge formalisms faithfully, specifically, and unambiguously perform as intended. Validation may occur across tiers of functionality and levels of representation as well as for varying degrees of composition across levels and tiers (Levels of Representation by Tiers of Functionality). Validation may occur within and across various activities within the knowledge engineering lifecycle development process. Information (e.g., “gold standard” results) and tooling (e.g., comparison, profiling, grading) may be reused or repurposed across these activities.
The two main phases where knowledge validation occurs is at the computable logic formalization stage and the local implementation stage. A related effort is input data validation (for local implementations) to ensure that an accurate and sufficient input data substrate for the computable formalisms to reason over is not a source of error in the computed or inferred results or that additional data or enrichment logic may be required in order for the knowledge expressions to infer results (i.e., information and insights) as intended.
In the case where the knowledge engineering activities, or part thereof, occur outside the context of a representative implementation target data set(s), test data sets or test cases must be created as part of the knowledge engineering activities. Tooling exists for some types of formalisms (e.g., for quality measures) to facilitate this activity. This test data creation activity typically occurs within and/or across the knowledge acquisition and translation activities concurrent with and as a means of communicating the intended behavior of the knowledge expressions. Synthetic data sets and/or de-identified data sets may help accelerate and improve the activities of test case generation.
However, this process of developing against test data, performing logic validation against similarly manufactured (and possible refined) test data, then validating input data for local implementations, and finally validating fairly sophisticated logic in the context of validated input data is often a lengthy, labor-intensive, and complex process- often drought with error and non-value-add iteration. Moreover, it can also lead to significant rework in the design and development of logic expressions that require a full pass through the entire validation sequence very late in the knowledge engineering lifecycle. This is one of the key arguments for performing knowledge engineering against Real-World Data as described in the section on Knowledge Implementation, and performing Test-driven Knowledge Engineering as is discussed in the section in the Agile CPG Development Approach.
IG © 2023+ HL7 International / Clinical Decision Support. Package hl7.fhir.uv.cpg#2.0.0 based on FHIR 4.0.1. Generated 2024-11-26
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change