Sparked Logical Models
0.0.1 - CI Build
Australia (AUS)
Sparked Logical Models
0.0.1 - CI Build
Australia (AUS)
Sparked Logical Models, published by CSIRO. This guide is not an authorized publication; it is the continuous build for version 0.0.1 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/aehrc/logical-model-web/ and changes regularly. See the Directory of published versions
| Official URL: https://aehrc.csiro.au/fhir/logical-models/ImplementationGuide/au.csiro.fhir.logical-models | Version: 0.0.1 | |||
| Draft as of 2024-04-19 | Computable Name: SparkedLogicalModels | |||
As part of funding in the 2023-24 Federal Budget to implement new initiatives to improve digital health information sharing, the Australian Government provided $15.7 million over two years to progress national health information sharing priorities. This included $9.3 million over two years for the CSIRO to work with all Australian Governments, the Australian Digital Health Agency and the health technology industry to develop and adopt national Fast Healthcare Interoperability Resources (FHIR) standards.
In August 2023 an Australian first FHIR accelerator, ‘Sparked’, was launched with the aim of delivering a core set of FHIR standards for use in Australian settings over the next two years, developed by and for the community.
The Sparked program, run by the CSIRO Australian e-Health Research Centre (AEHRC) is a collaborative consortium incorporating the expertise of:
Through community collaboration and consensus, the CSIRO has begun to develop an Australian (AU) Core Data for Interoperability (AUCDI) and support the development of an associated AU Core FHIR Implementation Guide for delivery by 2025. This document describes the first release of the AUCDI.
The Core FHIR Implementation Guide is critical to ensuring that national standards incorporate localised data requirements where there are differences to the international FHIR format. For example, the AU Core will need to cater for identifiers from our Healthcare Identifiers Service to identify patients and consumers.
The CSIRO will develop an Australian (AU) eRequesting Dataset for Interoperability and support the development of an associated AU eRequesting FHIR Implementation Guide by June 2025 as the first use case, building off the FHIR AU Core.
By 2025, the Department of Health and Aged Care will develop a National FHIR Adoption Strategy and roadmap that will guide future Government and industry investment in FHIR standards.
Rather than building a top-down approach to standards, the CSIRO has taken a bottom-up approach, working with the community rather than dictating to them. This will ensure standards are more readily understood and adopted.
Community participation is critical for the success of Sparked. We strongly encourage the community to support Sparked, with details on the program and how to participate available on HL7 Australia and the CSIRO websites.
At the current time in Australia, most health data systems (e.g. EMRs) that exist are isolated from each other, within a single clinic or organisation, a health IT landscape characterised by multitude of fragmented silos. This occurs even witin the same sector, whether it be primary, acute or tertiary care. The structure of the health data contained within each system may be consistent only between clinics or organisations that use the same clinical system provided by the same vendor because of a shared proprietary and closed local data structure, however for large, multi-modular EMRs (e.g. hospital EMRs) the large implementation customisations can cause divergence in data collection. Between clinical systems there is currently little, if any, alignment. Unfortunately, any commonality in data structure is effectively due to luck rather than strategic or purposeful design.
This creates significant issues when clinicians need to share or exchange information between different clinical systems, when vendors try to develop value added services such as clinical decision support which uses data collected in different systems and when jurisdictions or other services want to collect and analyse data from multiple systems for population health information.
Exchange of health information has been difficult to date because each data set or clinical system has been developed locally, with fragmented, opaque and, often, proprietary ‘secret’ data structures. As a consequence, health data has needed to be mapped or transformed between clinical systems which results in the introduction of possible errors or potential loss of clinical data. Other data sets, such as national minimum data sets, are developed for secondary use rather than primary clinical use can place further data collection burdens on care providers.
The Australian Core Data for Interoperability (AUCDI) is intended to provide the initial foundation layer for an evolving ecosystem of agreed data models that has been purpose built to reflect clinical requirements for the data required to support provision of care, exchange, and aggregation for analysis, and to support clinical decision support. The AUCDI is exchange specification agnostic and vendor neutral, however it is based on an understanding of the functionality that exists in current multiple vendor systems.
The AUCDI describes and defines a common ‘lingua franca’ that identifies and leverages existing commonality between systems or suggests modifications or enhancements to systems, that will directly support low friction system-to-system exchange without the requirement for transformation or mapping which can result in errors or loss of data.
Release 1 of the AUCDI is focussed on agreement of “the core of the core” common data elements to enable quality use of information within the record at the point of care by a care provider as well as enable the safe and meaningful exchange of information to other care providers.
While AUCDI itself is agnostic of any exchange standard, the AUCDI informs the clinical data requirements for the development of the FHIR Implementation Guide for AU Core. This specification sets the minimum expectations on FHIR resources to support conformance and implementation in systems and sets minimum expectations for a system to record, update, search, and retrieve core digital health and administrative information associated with a patient. Further information on the relationship between AUCDI and AU Core can be found in [AUCDI, FHIR and AU Core Implementation Guide].
The AUCDI will potentially act as an agent for change by bridging between fragmented silos of data and providing a foundation of building blocks of standardised data that can be reused in multiple use cases and a variety of clinical specialties, geographical locations and professional contexts.
The AUCDI is a living, growing artefact and will be expanded in future iterations to support additional use cases – adding breadth through inclusion of new clinical data items, and depth by enhancement with further granular detail.
The primary intent of the Australian Core Data for Interoperability is to design and govern a collection of coherent, reusable building blocks known as ‘clinical information models’.
An information model is a technical term, commonly used in software engineering to describe the representation of data semantics.
In this data, each clinical information model describes the clinically agreed data structure, pattern and content for a single, discrete clinical concept. This includes:
the metadata descriptions about the clinical concept and its intended purpose, purpose and use;
one or more component data elements, each associated with attributes such as data types, allowed values and constraints; and
relationships between data elements.
Examples of clinical information models include, but are not limited to:
Adverse reaction risk;
Procedure completed; and
Problem/Diagnosis summary.
Some information models will be simple; others will represent a more complex grouping of related data. There will also be a variety of types of models, designed to support accurate representations of complex clinical data. For example:
multiple data elements that describe various attributes about a specific clinical concept such as a single ‘Procedure’ item; or
groupings of repeatable data elements
Each clinical information model is deliberately designed and created with the intent of re-use across many data sets, projects, clinical scenarios and geographical locations. Each one will vary in the level of detail, which will likely grow in granularity over time as requirements for re-use in different contexts is further understood.
This core data for interoperability is intended to provide a master set of information models that are inclusive of all relevant data elements and their attributes and, while informed by existing project data and priorities, is intended to be agnostic to any single project, application or intent. Data that might support a specific clinical scenario can be represented by a subset of this data, knowing that there would be consistency with data built to support another clinical scenario if they are both created using the same clinical information models. As projects and clinical systems increasingly use the same clinical information models, interoperability of data becomes orders of magnitude easier because of shared information models, minimising the need for data transformation and mapping.
This data for interoperability is intended as a living document and will be expanded in future projects to support additional use cases – adding breadth through addition of new clinical information models, and depth through enhancement with granular detail.
Within the information model, any data that is intended to be recorded as text can either be recorded as a free text narrative or it can be structured by selecting a word or phrase from a value set. Selection from a known and shared value set from a clinical terminology strongly supports consistency of data recording, including correct spelling and limiting data entry selection to clinically appropriate values. Re-use of agreed and validated terminology value sets within the clinical information models further enhance data exchange, clinical decision support, querying and analysis on health data.
In Australia, SNOMED CT-AU has been adopted as a standard for recording structured value sets in health records. In the Sparked program, SNOMED CT-AU is the primary terminology from which value sets will be derived to support standardised coded text entry in the AUCDI’s clinical information models. Other national terminologies such as LOINC are also included where appropriate.
Many SNOMED CT-AU value sets have already been developed through work in the Australian Digital Health Agency (the Agency) and it is intended to re-use these nationally agreed and published value sets where clinically agreed as appropriate.
The breadth of scope for the AUCDI means that there are many value sets that have not been previously developed and so new SNOMED CT-AU value sets are being developed to match the requirements of the information models.
The AUCDI focuses on core data required for patient care including clinical data entry, data use and sharing information to support healthcare delivery. The AUCDI is not static and is intended to grow over time as standards mature and users’ needs evolve.
It is important to find the balance between supporting current clinical practice and technical system implementation to build a foundation to safely support core common data and defining the perfect data , extensive data model. industry and policy.
The first release of AUCDI (R1) has been built as the beginning foundation on which further data groups and elements could be iteratively added as users’ requirements are clarified and defined, and policies and technical implementations mature and develop.
Key considerations in developing R1 were
To include data that is well understood by users and are well supported by existing implementations across multiple use cases.
Identifying incremental change that will create benefit and not not add any clinical risk
Data elements that required further consultation or were not yet well implemented were excluded from R1 and have been placed in the backlog for future releases.
To create a starting block to build upon, avoiding breaking changes in the future as much as possible.
While building the AUCDI, it is important to avoid needing to undo or rework content that has already been defined can be costly for implementations and users.
In order to help us focus our efforts and aid to define the scope of R1, scope drivers were identified. Due to the extensive international engagement and acceptance It was agreed that the clinical content for a health summary, guided by the clinical concepts from the International Patient Summary) would be used to identify data groups and data elements to be included in R1. This clinical content would then be able to underpin any type of health summary such as transfer of care summaries but also chronic disease management, decision support tools like cardiovascular risk calculators and referrals.
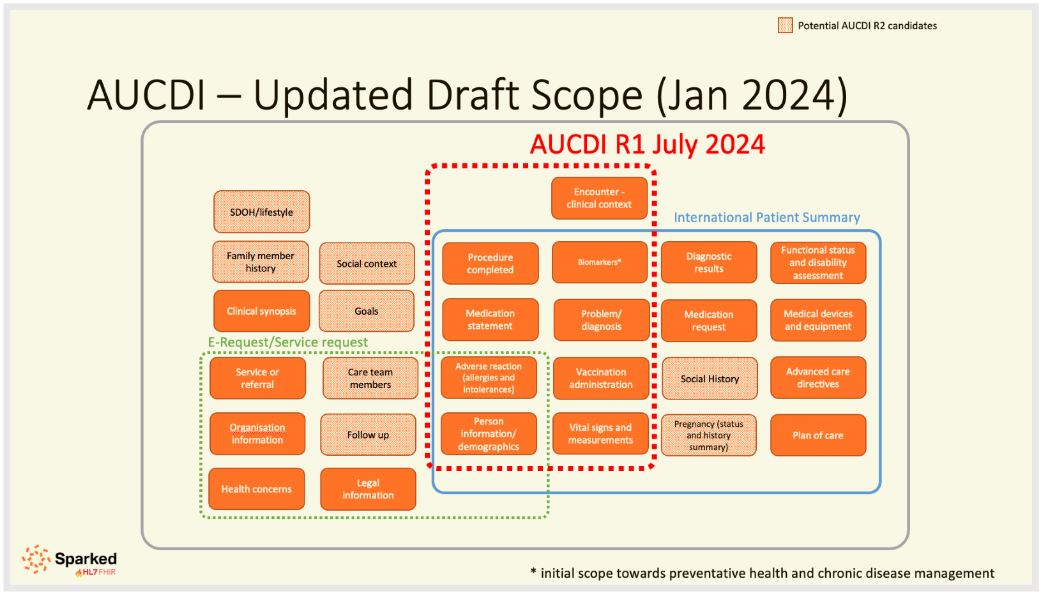
The scope of AUCDI R1 is a subset of the International Patient Summary and some encounter information. It is intended that the scope will expand in further iterations of the AUCDI.
The scope of AUCDI includes:
In R1, the data models developed across the scope area included are by no means complete, but the beginnings, “the core of the core”, on which to further build upon and fill out as AUCDI progresses and further use cases and requirements mature.
While AUCDI defines the clinical requirements of the clinical information that should be included for data entry, data use and sharing of information supporting patient care, It does not define “how” the data is exchange as it is data exchange standard agnostic.
FHIR is the next-generation HL7 standard for exchanging healthcare data electronically. It is based on the lessons learnt from the many years of developing previous HL7 standards for healthcare data exchange.
The basic building blocks of FHIR, Resources, can be tailored to suit specific use cases by “profiling”. Whilst FHIR is an international standard, national and regional projects can provide localisation of resources. HL7 Australia’s “AU Base” Implementation Guide provides localisation of resources for the Australian context and AU Core defines the Data model and RESTful API interactions that set minimum expectations for a system to record, update, search, and retrieve core digital health and administrative information associated with a patient.
AU Core FHIR IG has been developed in reference to the AUCDI . This integration links the standardised AUCDI datasets to their representations in FHIR.
A collaborative community co-design process was established to reach consensus with the clinical profession and software industry on the core common data items required in the AUCDIi.
The initial design of the AUCDI commenced with an analysis of existing data in primary care clinical systems, national and international standards, existing FHIR resources and openEHR archetypes.
Previous work done as part of CSIRO’s Primary Care Data Quality Foundation work which developed a Primary Care Data Dictionary which provided the initial foundation layer for an evolving ecosystem of agreed and publicly available health data that has been purpose built to reflect clinical requirements for provision of care, data exchange, and aggregation for analysis, and to support clinical decision support. Release 1 of the Data Dictionary was focussed on agreement of the core common data elements to enable quality use of information within the record at the practice as well as enable the safe and meaningful exchange of information to other care providers and which was enhanced and extended in the second release to support a range of health assessment clinical scenarios. Decisions about the level of detail included had been pragmatic and intended to align or extend existing vendor data models where possible and to support clinical priorities for adding structured data that will impact patient care. The content of SNOMED CT-AU informed the clinical information models as well as providing the value sets.
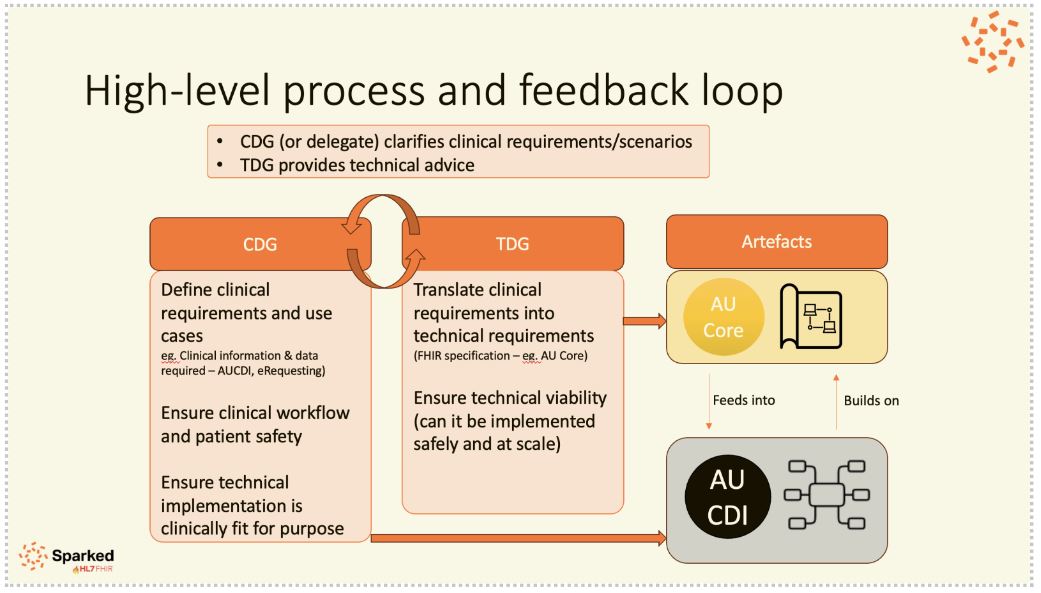
The approach to design of the AUCDI has incorporated the following processes
Open collaborative, consensus driven approach
Clinical data design group
Open feedback process
Core design principles
A Clinical data design group was established asdfjkasdfjkasf
The purpose of Sparked Clinical Design Group was to:
Assist in the prioritisation and development of the Data Sets for Interoperability
Meet monthly to understand clinical requirements for the AUCDI/AUeReqDI and to review draft AUCDI / AUeReqDI and to address the consultation objectives and consider the content of the AUCDI / AUeReqDI, implementation considerations and risks
Interact with the Sparked AU Core Technical Design Group and Sparked eRequesting Technical Design Groups as required to ensure as much alignment as possible between the groups
Numbers of members, attendees etc., number of workshops, etc.
If there was not consensus regarding a concept or data element, or the specification was not mature, it was pushed toward a future release, pending further discussion and agreement.
The AUCDI is intended to gradually build a collection of re-usable clinical information models and associated SNOMED CT-AU value sets that will provide a foundation for a standardised health data ecosystem.
To assist the development of AUCDI and to focus allow prioritisation by the Sparked team, the CDG and its collaborators, 8 design principles were developed at the first CDG workshop in September 2023. The details of the design principles are in the table below.
| Design Principles | Rationale | Approach |
|---|---|---|
| Reduce duplication - Single entry, single development (multiple use and reuse) | Well-structured clinical data defined at the point of collection should be able to be reused for multiple use cases (e.g. clinical decision support, reporting and analytics). This reduces burden of effort on care providers to record similar versions of the same information in multiple different locations. It can also help reduce the need for an individual to share their information multiple times in different settings. | Supporting preventative care/chronic disease management to drive clinical decision support, considering secondary use data sets e.g. AIHW primary care data model, PIP QI |
| Supports patient centred care - driven by a clinical quality and safety use case | Person-centred care is widely recognised as a foundation to safe, high-quality health care. It is care that respects and responds to the preferences, needs and values of patients and consumers. (https://www.safetyandquality.gov.au/our-work/partnering-consumers/person-centred-care) | Engaging with clinicians from the beginning across the health ecosystem Looking at agreed national clinical standards and guidelines |
| Not data for data’s sake | Before collecting data, it should be important to understand what use case it serves so as not to burden the care provider with collecting data that is of little to no value | Starting with “core of the core” and growing iteratively |
| Driven by primary clinical data use not secondary data use needs | Clinical data collection should be driven by primary use first – clinical use; however secondary use should still be considered. If data collection for primary use is designed correctly, it should be able to be reused and aggregated for most secondary use cases | Considering secondary use data sets e.g. AIHW primary care data model, PIP QI, etc. Looking towards data that can be reused for secondary uses |
| Supports best practice care, clinical guidelines and clinician workflow | Provision of care must be in accordance with minimum evidence-based standards, guidelines and protocols. Standardised health data should support best practice care, clinical guidelines and care provider workflow. |
Engaging with clinicians across the health ecosystem from the beginning Looking at agreed national clinical standards and guidelines |
| Systems can support now or with minimal effort, supporting a strategic roadmap with an agile iterative process | Aligned with AU Core, looking at US Core Meetings with vendors and survey to go out to TDG to validate |
|
| Leverage agreed national health data standards | To seamlessly exchange or access health information and ensure consistent understanding, it is essential to use nationally agreed digital health standards, specifications and terminology | Using agreed national clinical and technical standards – FHIR, SNOMED CT, LOINC, clinical standards e.g. RACGP Clinical guidelines |
| Involve and consider all healthcare domains and care modalities | Engaging with clinicians, jurisdictions and industry from across the health ecosystem |
There are a number of similar programs of work occurring around the world. Of interest is the USA, UK and Canada
USCDI
The Office of the National Coordinator for Health Information Technology (ONC) in the US have developed the United States Core Data for Interoperabiity (USCDI).
PRSB
In the UK, the Professional Records Body (PRSB) has developed the Core Information Standard. The core information standard is a standard for sharing information in health and care record. It is a consensus and evidence-based standard that defines a set of information that can potentially be shared between systems in different sites and settings, among professionals and people using services.
The PRSB is working closely with the NHS Digital interoperability team to align V2.0 to the UK core R4 FHIR profiles. This is in progress and with work completed on many areas such as person demographics, allergies and adverse reactions, medications and medical devices.
IPS
Pan Canadian Health Data Framework
Expected that it will be used in diff ways for different use cases
Different modes of use – different terminolgoies - recommended
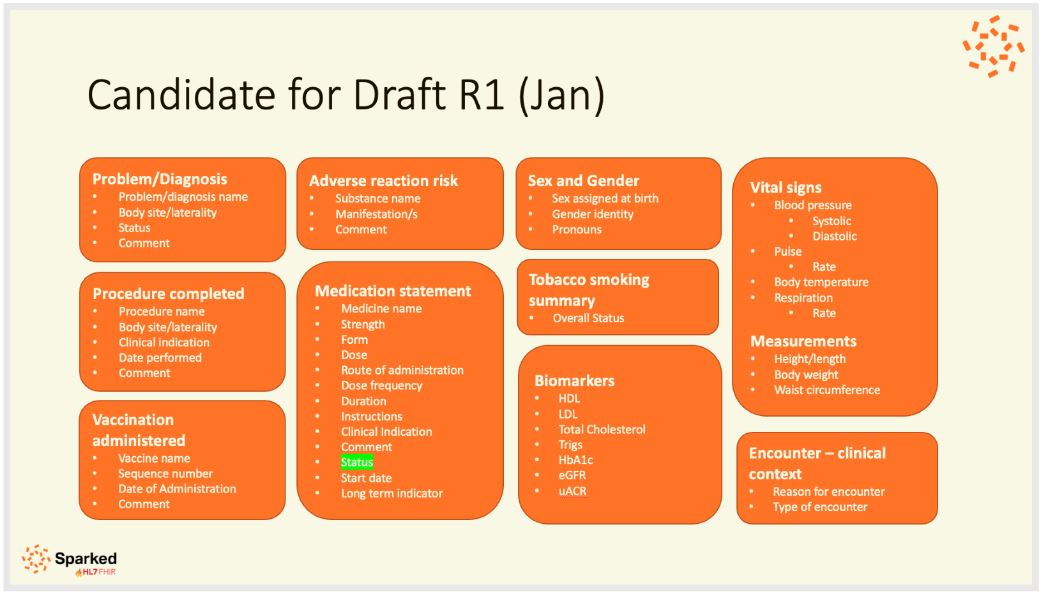
This section of the document describes the data groups and elements that make up the AUCDI
AUCDI R1 is composed of the data groups and elements as shown in diagram below.
This data group is used to record an assessment of the propensity for an individual to experience an adverse reaction if exposed, or re-exposed, to a specified substance or class of substances, and an overview of each related reaction event.
IG © 2021+ CSIRO. Package au.csiro.fhir.logical-models#0.0.1 based on FHIR 4.0.1. Generated 2024-04-19
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change